Apresentação
Um programa de computador existe para resolver problemas do dia a dia, organizando tarefas e informações. Para isso, quem desenvolve o software divide o problema em partes menores e cria um passo a passo, chamado de algoritmo, que orienta o computador sobre o que fazer, sempre pensando em como usar bem o tempo e a memória.
No centro de tudo estão os tipos de dados, que funcionam como uma “tradução” das informações do nosso mundo para a linguagem do computador. Eles transformam textos, números, datas e respostas de sim ou não em formatos que a máquina entende, ou seja, sequências de zeros e uns, chamadas de bits. É graças aos tipos de dados que o computador sabe se está lidando com números inteiros, números com casas decimais, textos, listas, datas ou informações do tipo verdadeiro/falso.
Cada tipo de dado permite operações específicas: números podem ser somados, textos podem ser concatenados (juntos), listas podem ser pesquisadas. Além disso, cada tipo ocupa um espaço diferente na memória. Normalmente, quando o programa recebe dados, tudo chega como texto; depois, esses dados precisam ser transformados para o tipo certo antes de serem usados. Ao apresentar o resultado, o processo é invertido, convertendo os dados para formatos compreensíveis, como texto, tabelas ou outros formatos que as pessoas conhecem.
Sem tipos de dados, seria fácil confundir números com textos, datas ficariam fora de ordem e valores vazios poderiam causar erros. Por isso, os tipos de dados tornam o funcionamento interno do computador possível, mais seguro e eficiente.
Por dentro, o computador é feito de peças muito pequenas chamadas transistores, que só conseguem representar dois estados: ligado ou desligado, isto é, zero ou um. Toda a informação é guardada como sequências desses bits. Os tipos de dados indicam ao computador como interpretar essas sequências, se são números, letras, imagens ou outros tipos de informação.
O computador tem partes principais: a CPU (o “cérebro”), a memória (onde os dados ficam temporariamente), dispositivos de armazenamento (como disco rígido ou SSD) e os aparelhos para entrada e saída de dados (teclado, mouse, tela, impressora). A CPU lê os dados da memória, faz operações e devolve os resultados. O modo como os dados são organizados influencia a rapidez e exatidão do computador.
No software, usamos tipos de dados para organizar e proteger a informação, evitando erros e tornando o código mais fácil de entender. Por exemplo, ao criar um programa, decidimos que “idade” é um número inteiro positivo (porque não faz sentido ter idade negativa), “nome” é um texto, “lista de compras” é uma lista de textos, e assim por diante. Isso impede confusões e facilita futuras alterações no programa.
Dica: É muito importante ler a série de artigos sobre Computação para Iniciantes(abre em nova janela) para entender melhor tudo que está sendo apresentado aqui.
Como as linguagens de programação lidam com tipos de dados
Nas linguagens de programação, existem dois estilos principais:
-
Tipagem Estática: Neste caso, o computador confere os tipos de dados antes de executar o programa (ou seja, ele verifica quais dados serão inteiros, textos, listas e outros), ajudando a evitar erros logo no começo.
-
Tipagem Dinâmica: Aqui, o computador só verifica os tipos de dados enquanto o programa está funcionando, ou seja, durante a execução. Isso quer dizer que os tipos podem mudar conforme o programa vai sendo executado, oferecendo mais flexibilidade, porém com maior risco de erros.
Algumas linguagens obrigam à conversão entre tipos; outras são mais flexíveis, mas podem causar erros inesperados.
- Exemplos de linguagens com tipagem estática:
- C
- C++
- Java
- Rust
- Go
- TypeScript
- Exemplos de linguagens com tipagem dinâmica:
- Python
- Ruby
- JavaScript
- PHP
Critérios como desempenho, segurança e facilidade de uso influenciam a escolha entre tipagem estática e dinâmica. Cada abordagem tem suas vantagens e desvantagens, e a escolha depende do tipo de projeto e das necessidades específicas.
Tipos de dados em Ruby
Ruby é uma linguagem de programação que funciona de forma dinâmica e baseada em objetos. Isso quer dizer que, quando você usa Ruby, tudo é considerado um objeto. Além disso, você não precisa se preocupar em dizer qual é o tipo de dado de cada coisa, porque o próprio Ruby descobre isso automaticamente, de acordo com o valor que você coloca.
Por exemplo:
- Se você escreve
idade = 25, o Ruby entende que “idade” é um número inteiro. - Se você escreve
nome = "Ana", o Ruby entende que “nome” é um texto. - Se você escreve
altura = 1.75, o Ruby entende que “altura” é um número com casas decimais.
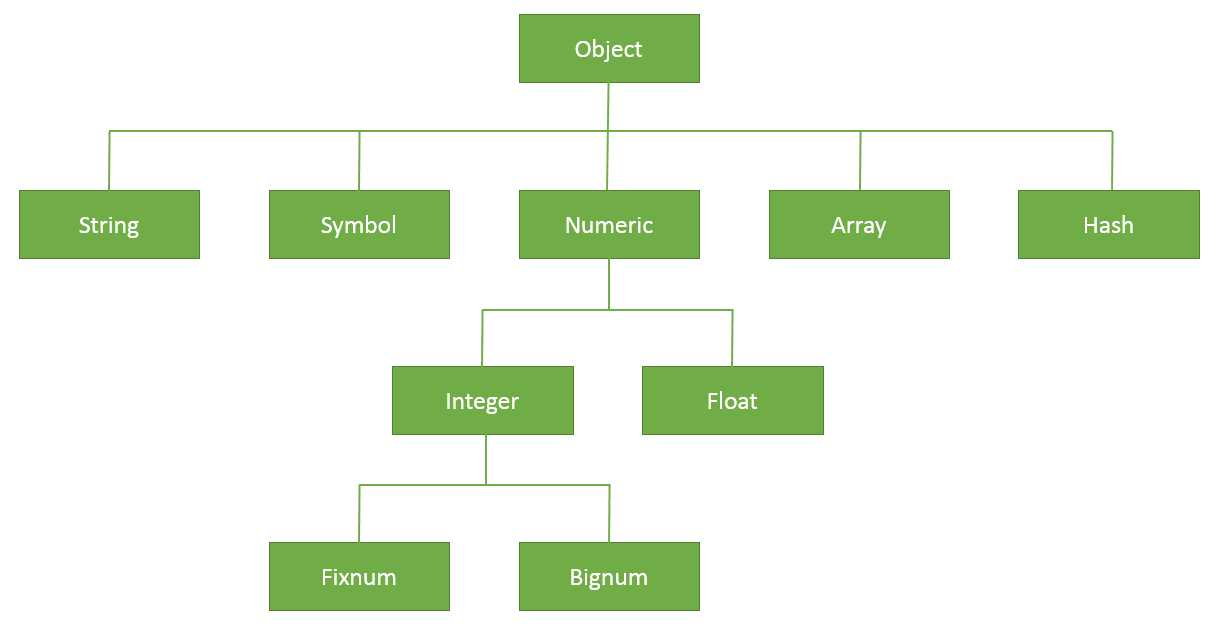
Veja os tipos de dados que mais aparecem em Ruby:
-
Números Inteiros (Integer): São números sem parte decimal. Podem ser positivos ou negativos, como
42e-7. Eles servem para contagens e cálculos que não precisam de parte decimal (parte decimal é a parte do número que vem depois do ponto ou vírgula). -
Números com vírgula (Float ou Ponto Flutuante): Permitem guardar números com vírgula, como
3.14e-1.001. São úteis para medidas e valores que não são inteiros (que têm parte decimal), como2.000123,123.0e15.75.Por que chamam de “ponto flutuante”? Imagine que o computador guarda esses números como se fossem peças de lego que podem deslizar para a esquerda ou para a direita, conforme o tamanho do número. Por exemplo, para guardar
0.000123, ele “empurra” a vírgula (ou ponto) para frente até virar1.23, lembrando depois quantos espaços empurrou. Assim, o lugar da vírgula (ou ponto) pode “flutuar” (mudar de posição), por isso o nome “ponto flutuante” ou “float”.Na prática: Por causa desse jeito de guardar os números, às vezes as contas dão resultados com pequenas diferenças, como quando tentamos somar
0.1 + 0.2e o resultado aparece como0.30000000000000004. Isso é normal e acontece em todos os computadores porque eles nem sempre conseguem representar todos os números decimais com perfeição. Por isso é importante estar atento a essas pequenas diferenças ao trabalhar com números de ponto flutuante, pois se precisamos de muita precisão, como em cálculos financeiros, devemos usar outras técnicas ou bibliotecas específicas para evitar esses erros. -
Textos (Strings): São textos, ou seja, uma sequência de letras, números ou símbolos que não servem para cálculos e sim para representar informações. Exemplos:
"Olá, Mundo!"e"12345". Usamos strings (texto) para guardar nomes, frases e qualquer informação textual. -
Verdadeiro ou falso (Boolean ou Booleano): Neste tipo de dado só existem duas opções possíveis: verdadeiro (
true) ou falso (false). Ideais para tomar decisões no código quando estiver programando.
Uma aplicação prática dos booleanos: Imagine que você está criando um programa e nesse programa existe uma área só para pessoas cadastradas. Para permitir o acesso, você pode usar um booleano para verificar se a pessoa está cadastrada ou não. Se estiver cadastrada, o valor será true (verdadeiro) e ela poderá entrar e acessar; se não estiver cadastrada, o valor será false (falso) e o acesso será negado podendo exibir uma mensagem como “Acesso negado” ou “você não possui cadastro”. Assim, os booleanos ajudam a controlar o fluxo do programa com base em condições simples de verdadeiro ou falso.
- Listas (Arrays): São listas que guardam vários valores juntos, como
[1, 2, 3]ou["maçã", "banana", "laranja"]. Ajudam a organizar dados em sequência.
O ideal é que os dados dentro de um array tenham relação entre si, ou seja, que façam parte do mesmo grupo ou categoria. Por exemplo, uma lista de frutas, uma lista de números inteiros ou uma lista de nomes de pessoas. Isso facilita o uso e a manipulação dos dados dentro do array.
- Tabelas de pares (Hashes): Este tipo de dado guarda pares de informações, onde nós temos uma chave e um valor associado a essa chave. Por exemplo:
{ "nome" => "João", "idade" => 30 }. Aqui, “nome” e “idade” são as chaves, e “João” e 30 são os valores correspondentes. Hashes facilitam encontrar um valor usando a chave.
Entendendo melhor: Pense em um hash como uma mini agenda ou dicionário, onde você tem uma palavra (chave) e a definição ou informação relacionada a essa palavra (valor). Você pode procurar o valor usando a chave, assim como você procura o significado de uma palavra no dicionário. Por exemplo, em um hash que guarda informações de uma pessoa, você pode ter a chave "nome" com o valor "Ana", e a chave "idade" com o valor 25, além de outras informações como "cidade" com o valor "São Paulo".
- Nada (Nil): Mostra que não tem valor nenhum ali, está vazio.
nilsignifica “não tem nada”, não é a mesma coisa que zero ou um espaço em branco no texto.
Por que isso é importante: É preciso sempre lembrar que o computador não sabe de nada por conta própria, tudo precisa ser dito para ele, ele deve ser orientado porque ele não deduz, não advinha e não tem senso comum como nós humanos temos. Então assim como precisamos informar alguma informação, também precisamos informar quando não existe informação nenhuma.
- Símbolos (Symbols): São parecidos com textos, mas são usados para representar nomes e servem para identificar coisas de forma única no código, coisas que não vão mudar. Siglas de Estados do Brasil, por exemplo, são bons usos para símbolos, como
:SPpara São Paulo e:RJpara Rio de Janeiro, pois essas siglas não mudam ou mudam muito dificilmente.
Onde as informações são guardadas?
Já vimos que os tipos de dados classificam as informações que usamos em nossos programas, mas onde essas informações são realmente guardadas? Como acontece essa classificação?
As informações nos programas são guardadas em variáveis. Variáveis são como “caixinhas” onde colocamos os dados que queremos usar. Cada variável tem um nome, e esse nome ajuda a identificar o que está guardado ali.
É a variável que vai ter o tipo de dado que a informação representa, seja um número, um texto, uma lista ou outro tipo.
Por exemplo, quando escrevemos:
idade = 25
nome = "Ana"
altura = 1.75
Aqui o Ruby está criando três variáveis: “idade”, “nome” e “altura”. O Ruby automaticamente reconhece que “idade” é um número inteiro, “nome” é um texto e “altura” é um número com vírgula, pois lembrando que Ruby é uma linguagem de tipagem dinâmica, então ele identifica o tipo de dado com base no valor que colocamos na variável, neste caso 25, “Ana” e 1.75.
Por que precisamos usar variáveis?
Usar variáveis é muito importante para criar programas. Sem variáveis, seria como tentar fazer contas sem anotar os números, ou seja, tudo teria que ser feito de uma vez só, o que deixaria o código difícil de entender e de arrumar depois.
As variáveis servem para guardar informações na memória do computador enquanto o programa está funcionando. Assim, você pode ler, mudar ou usar esses valores quantas vezes quiser.
Cada variável ocupa um lugar na memória, que tem um número próprio (um endereço de memória como por exemplo 0x7ffee4bff6c8). Mas, em vez de decorar esses números, a gente dá nomes para as variáveis, como idade ou nome, tornando tudo mais fácil de entender.
Por exemplo, quando você escreve:
idade = 25
No Ruby, isso cria uma variável chamada idade e coloca nela o número 25. Esse valor fica guardado na memória. Depois, toda vez que você usar idade no programa, o Ruby vai buscar o número 25 que está guardado nesse lugar.
Por baixo dos panos, o Ruby busca o número 25 da variável idade em um endereço de memória específico que se parece com 0x7ffee4bff6c8, mas você não precisa se preocupar com isso, pois o Ruby cuida dessa parte para você.
A relação entre nome e valor
Em programação, uma variável funciona como um nome que damos para guardar alguma informação na memória do computador. Por exemplo, se criamos uma variável chamada “idade”, esse nome está ligado a um valor, como 25. Ou seja, “idade” é só o jeito de identificar e acessar esse valor que está guardado (o 25 nesse caso).
No computador, tudo isso acontece usando endereços de memória, que são como locais onde os dados ficam armazenados. Em linguagens como C e C++, dá para ver e trabalhar nesses endereços diretamente usando algo chamado ponteiro. Um ponteiro é uma variável especial que, em vez de guardar um valor como um número ou texto, guarda o endereço de outro valor na memória.
Isso mostra que, no final das contas, toda variável aponta para um lugar específico onde a informação está guardada. Já em linguagens mais novas, como Ruby ou Python, o próprio programa cuida de guardar, acessar e apagar esses valores na memória automaticamente. Assim, quem está programando não precisa se preocupar em controlar esses endereços diretamente, pois tudo é feito de forma simples e automática.
Possibilidade de usar várias vezes a variável
As variáveis não servem só para guardar informações, mas também ajudam a deixar o código mais fácil de entender e reaproveitar. Em vez de escrever sempre os mesmos números ou nomes várias vezes no programa, você pode colocar esses valores em variáveis e usar quando precisar.
Por exemplo:
preco = 50
desconto = 0.1
preco_final = preco - (preco * desconto)
Explicando linha por linha:
- Na primeira linha, criamos uma variável chamada preco (que significa o preço de um produto) e colocamos nela o valor 50.
- Na segunda linha, criamos outra variável chamada desconto e colocamos nela o valor 0.1 (que representa 10% de desconto).
- Na terceira linha, criamos uma variável chamada preco_final (preço final) que calcula o preço final do produto aplicando o desconto.
preco - (preco * desconto)significa que estamos pegando o valor do preço (que é 50) e subtraindo (fazendo uma conta de menos) o valor do desconto (que é 10% de 50, que vai dar 5). O resultado final será 45 e vai ser guardado na variável preco_final.
A vantagem de usar variáveis é que, se você quiser mudar o preço ou o desconto, basta alterar o valor na variável uma vez só, e o resto do código vai funcionar corretamente sem precisar mudar nada mais nos cálculos ou em qualquer lugar no código onde essas variáveis são usadas. Isso torna o código mais fácil de manter e entender.
Além disso, fica simples saber o que cada valor significa, porque os nomes das variáveis ajudam a explicar o que está sendo guardado ali. Isso é diferente do que se tivessemos só os números soltos no código, que podem ser confusos e não explicam nada sobre o que cada um representa.
Por que não pode usar espaços, acentos ou símbolos nos nomes das variáveis?
Quando escrevemos código, o que parece ser apenas “texto comum” para a gente, na verdade é um monte de comandos que o computador precisa transformar em algo que ele entende. Quem faz essa transformação é um programa chamado interpretador (como no Ruby) ou compilador (em linguagens como C, Java, Go, entre outras).
Esses programas seguem regras bem certinhas, chamadas de gramática da linguagem (ou sintaxe), que dizem exatamente o que pode ou não pode ser usado. Por isso, o nome de uma variável, também chamado de identificador, precisa seguir essas regras para que o computador saiba onde ele começa e termina.
Por exemplo, se você tentar escrever:
idade da pessoa = 25
O Ruby não vai entender “idade da pessoa” como um nome só. O espaço faz ele pensar que “idade” é uma coisa, “da” é outra e “pessoa” outra, e aí dá erro porque ele entende que são três coisas diferentes tentando receber um valor só.
Isso também vale para acentos (tipo á, é, ç) e símbolos (@, #, !, -, ? etc.), porque esses sinais já têm funções próprias na linguagem.
Por isso, o interpretador não deixa usar esses caracteres nos nomes das variáveis, evitando confusão na hora de entender o código.
Uso do sublinhado (_) e do traço (-)
Para separar palavras nos nomes das variáveis e deixar o código mais fácil de ler, foram criadas algumas formas padrão. O sublinhado (_) é muito usado porque a maioria das linguagens de programação aceita ele e normalmente ele não serve para outra coisa.
Exemplo:
idade_da_pessoa = 25
nome_do_aluno = "João"
Assim, o interpretador entende que se trata de um nome só, mesmo tendo várias palavras.
Esse jeito de escrever nomes com sublinhado é chamado de snake_case (caso da cobra), porque lembra o formato de uma cobra se arrastando.
O traço (-), por outro lado, não é usado em nomes de variáveis na maioria das linguagens de programação, porque ele já tem outra função: representar a operação de subtração (de tirar um número do outro).
Exemplo:
idade-da-pessoa = 25
pode dar erro ou confusão. O traço só é usado em situações específicas, como nomes de arquivos (minha-imagem.png) ou meu-arquivo.rb.
Linguagens de programação como o Clojure permitem o uso do traço (hífen) em nomes de variáveis, mas isso é uma exceção e não a regra geral.
Jeitos de escrever nomes (convenções de nomenclatura)
Com o tempo, surgiram vários padrões para deixar o código mais organizado e fácil de entender. Os mais comuns são:
- snake_case: Usado em linguagens como Ruby, Python e C, utiliza o sublinhado (_) para separar as palavras.
- Exemplo:
idade_da_pessoa,total_de_compras.
- Exemplo:
- camelCase: Usado em linguagens como JavaScript, Java e C#, a primeira palavra começa com letra minúscula e as seguintes começam com letra maiúscula, sem espaços ou sublinhados.
- Exemplo:
idadeDaPessoa,totalDeCompras.
- Exemplo:
- PascalCase: Utilizado para nomes de classes e módulos, todas as palavras começam com letra maiúscula, sem espaços ou sublinhados.
- Exemplo:
PessoaCliente,ContaBancaria.
- Exemplo:
- kebab-case: Usa o traço (-) para separar as palavras. É comum em HTML, CSS e nomes de arquivos.
- Exemplo:
botao-enviar,pagina-principal.
- Exemplo:
Esses jeitos não são obrigatórios pelo interpretador, mas são boas práticas que as pessoas desenvolvedoras seguem para manter o código organizado e fácil de entender por outras pessoas (ou por elas mesmas no futuro). Seguir essas convenções ajuda a evitar confusões e torna o trabalho em equipe mais eficiente.
Praticando os tipos de dados no IRB
Para tornar mais palpável (concreto e real) o que vimos até agora, vamos usar o IRB (Interactive Ruby) para experimentar os tipos de dados com as variáveis.
Vamos criar algumas variáveis:
- nome_aluno = “Ana”
- idade_aluno = 10
- turma = “5º ano”
- nota_1 = 8.5
- nota_2 = 9.0
- nota_3 = 7.5
- nota_final = (nota_1 + nota_2 + nota_3) / 3
E depois vamos mostrar na tela a mensagem com as informações do aluno. Esse processo no IRB ficaria assim:
irb(main):013> nome_aluno = "Ana"
=> "Ana"
irb(main):014> idade_aluno = 10
=> 10
irb(main):015> turma = "5º ano B"
=> "5º ano B"
irb(main):016> nota_1 = 8.5
=> 8.5
irb(main):017> nota_2 = 9.0
=> 9.0
irb(main):018> nota_3 = 7.5
=> 7.5
irb(main):019> nota_final = (nota_1 + nota_2 + nota_3) / 3
=> 8.333333333333334
irb(main):020> puts "O aluno (a) #{nome_aluno}, de #{idade_aluno} anos, da turma #{turma}, teve a nota final #{nota_final.round(1)}."
O aluno (a) Ana, de 10 anos, da turma 5º ano B, teve a nota final 8.3.
=> nil
irb(main):021>
Explicando linha por linha do que foi feito no IRB:
irb(main):013> nome_aluno = "Ana"- Criamos uma variável chamada
nome_alunoe colocamos nela o texto"Ana".
- Criamos uma variável chamada
irb(main):014> idade_aluno = 10- Criamos uma variável chamada
idade_alunoe colocamos nela o número10.
- Criamos uma variável chamada
irb(main):015> turma = "5º ano B"- Criamos uma variável chamada
turmae colocamos nela o texto"5º ano B".
- Criamos uma variável chamada
irb(main):016> nota_1 = 8.5- Criamos uma variável chamada
nota_1e colocamos nela o número8.5.
- Criamos uma variável chamada
irb(main):017> nota_2 = 9.0- Criamos uma variável chamada
nota_2e colocamos nela o número9.0.
- Criamos uma variável chamada
irb(main):018> nota_3 = 7.5- Criamos uma variável chamada
nota_3e colocamos nela o número7.5.
- Criamos uma variável chamada
irb(main):019> nota_final = (nota_1 + nota_2 + nota_3) / 3- Criamos uma variável chamada
nota_finalque calcula a média das três notas somandonota_1+nota_2+nota_3e dividindo o resultado por 3.
- Criamos uma variável chamada
irb(main):020> puts "O aluno (a) #{nome_aluno}, de #{idade_aluno} anos, da turma #{turma}, teve a nota final #{nota_final.round(1)}."- Aqui usamos o comando
putspara mostrar na tela uma mensagem que inclui o nome do aluno, a idade, a turma e a nota final arredondada para uma casa decimal. "O aluno (a)é o texto fixo que aparece na mensagem.#{nome_aluno}insere o valor da variávelnome_alunona mensagem onde o#serve para indicar que queremos colocar o valor da variável ali.de #{idade_aluno} anosinsere o valor da variávelidade_aluno.da turma #{turma}insere o valor da variávelturma.teve a nota final #{nota_final.round(1)}quer dizer que vamos mostrar o valor da variávelnota_final, mas o.round(1)serve para indicar que queremos arredondar (aproximar) esse número para uma casa decimal só (por exemplo, 8.3333 vira 8.3).- Se a gente quisesse mostrar a nota final sem arredondar, poderíamos usar só
#{nota_final}, ou se quissesse arredondar para três casas decimais, usaríamos#{nota_final.round(3)}. - O resultado que aparece na tela é:
O aluno (a) Ana, de 10 anos, da turma 5º ano B, teve a nota final 8.3.
- Aqui usamos o comando
Trabalhando com verdadeiro ou falso (booleanos) no IRB
Agora vamos ver como trabalhar com o tipo de dado booleano (verdadeiro ou falso) no IRB. Vamos criar uma variável que indica se o aluno foi aprovado ou não, considerando que a nota mínima para aprovação é 7.0.
irb(main):021> nota_minima = 7.0
=> 7.0
Agora vamos criar uma variável chamada aprovado que vai guardar um valor booleano (true ou false que é verdadeiro ou falso em inglês) dependendo se a nota_final é maior ou igual à nota_minima.
irb(main):022> aprovado = nota_final >= nota_minima
=> true
Aqui, usamos o operador de comparação >= que significa “maior ou igual a”. Se a nota_final for maior ou igual à nota_minima, a variável aprovado vai receber o valor true (verdadeiro); caso contrário, vai receber false (falso).
Neste caso, como a nota_final é 8.3, que é maior que 7.0, a variável aprovado recebe true porque 8.3 é maior que 7.0.
Agora vamos mudar as notas para ver o que acontece quando o aluno não é aprovado. Vamos definir novas notas:
irb(main):023> nota_1 = 4.5
=> 4.5
irb(main):024> nota_2 = 2.3
=> 2.3
irb(main):025> nota_3 = 1.2
=> 1.2
irb(main):026> nota_final = (nota_1 + nota_2 + nota_3) / 3
=> 2.6666666666666665
irb(main):027> puts "O aluno (a) #{nome_aluno}, de #{idade_aluno} anos, da turma #{turma}, teve a nota final #{nota_final.round(1)}."
O aluno (a) Ana, de 10 anos, da turma 5º ano B, teve a nota final 2.7.
=> nil
irb(main):028> aprovado = nota_final >= nota_minima
=> false
Aqui, depois de mudar as notas para valores mais baixos, a nota_final ficou em 2.7, que é menor que a nota_minima de 7.0. Por isso, quando verificamos se o aluno está aprovado com a linha aprovado = nota_final >= nota_minima, a variável aprovado recebe o valor false (falso), indicando que o aluno não foi aprovado.
Colocando isso em um programa fora do IRB
Para gerar um histórico do que está sendo feito no IRB, podemos criar um arquivo chamado aula_tipos_dados.rb e colocar todo o código que usamos no IRB lá dentro. Essa aula pode ficar na pasta projeto-ruby que criamos anteriormente para colocar o programa ola_mundo.rb.
Vamos criar o arquivo aula_tipos_dados.rb com o comando:
touch aula_tipos_dados.rb
Agora que temos o arquivo criado, vamos abrir ele no VS Code com o comando:
code aula_tipos_dados.rb
Dentro do arquivo aula_tipos_dados.rb, vamos colocar o seguinte código:
nome_aluno = "Ana"
idade_aluno = 10
turma = "5º ano B"
nota_1 = 8.5
nota_2 = 9.0
nota_3 = 7.5
nota_minima = 7.0
nota_final = (nota_1 + nota_2 + nota_3) / 3
puts "O aluno (a) #{nome_aluno}, de #{idade_aluno} anos, da turma #{turma}, teve a nota final #{nota_final.round(1)}."
aprovado = nota_final >= nota_minima
puts "O aluno (a) #{nome_aluno} está aprovado? #{aprovado}"
Vamos salvar o arquivo e depois executar o programa no terminal com o comando:
ruby aula_tipos_dados.rb
Teremos a seguinte saída no terminal:
parallels@ubuntu:~/projeto-ruby$ ruby aula_tipos_dados.rb
O aluno (a) Ana, de 10 anos, da turma 5º ano B, teve a nota final 8.3.
O aluno (a) Ana está aprovado? true
parallels@ubuntu:~/projeto-ruby$
Aqui, o programa mostra a mensagem com as informações do aluno e indica se ele está aprovado ou não, baseado na nota final calculada, neste caso retornando true porque a nota final é maior que a nota mínima.
Vamos agora mudar as notas para valores mais baixos, como fizemos no IRB, para ver o que acontece quando o aluno não é aprovado. Vamos alterar as linhas das notas para:
nota_1 = 2.5
nota_2 = 3.0
nota_3 = 3.5
Depois de fazer essa alteração, salvamos o arquivo e executamos novamente o programa com o comando ruby aula_tipos_dados.rb no terminal. A saída será:
parallels@ubuntu:~/projeto-ruby$ ruby aula_tipos_dados.rb
O aluno (a) Ana, de 10 anos, da turma 5º ano B, teve a nota final 3.0.
O aluno (a) Ana está aprovado? false
parallels@ubuntu:~/projeto-ruby$
Aqui, o programa mostra a mensagem com as informações do aluno e indica que ele não está aprovado, retornando false porque a nota final é menor que a nota mínima.
Ou seja, conseguimos ver como os tipos de dados funcionam na prática, tanto no IRB quanto em um programa Ruby fora do IRB.
Resumo
Neste artigo, exploramos os tipos de dados em Ruby, que são os elementos fundamentais para representar e organizar informações em nossos programas. Vimos que os tipos de dados funcionam como uma “tradução” entre as informações do nosso mundo e a linguagem do computador, transformando textos, números e outros dados em formatos que a máquina consegue entender e processar.
Aprendemos que existem duas abordagens principais nas linguagens de programação: a tipagem estática (onde os tipos são verificados antes da execução) e a tipagem dinâmica (onde os tipos são verificados durante a execução). O Ruby segue a tipagem dinâmica, identificando automaticamente o tipo de dado com base no valor que atribuímos à variável.
Conhecemos os principais tipos de dados em Ruby:
- Números Inteiros (Integer): Para valores sem casas decimais, como contagens e cálculos simples
- Números com vírgula (Float): Para valores com casas decimais, úteis em medidas e cálculos precisos, entendendo o conceito de “ponto flutuante” e suas limitações
- Textos (Strings): Para representar informações textuais como nomes, frases e mensagens
- Booleanos: Para valores de verdadeiro ou falso, essenciais para tomadas de decisão no programa
- Listas (Arrays): Para organizar múltiplos valores relacionados em sequência
- Tabelas de pares (Hashes): Para guardar informações em pares chave-valor, como um dicionário
- Nada (Nil): Para representar a ausência de valor, diferente de zero ou espaço vazio
- Símbolos: Para identificar elementos únicos no código que não mudam
Descobrimos onde as informações são guardadas através das variáveis, que funcionam como “caixinhas” nomeadas na memória do computador. Entendemos por que não podemos usar espaços, acentos ou símbolos nos nomes das variáveis devido às regras do interpretador, e como o sublinhado (_) nos ajuda a separar palavras nos nomes.
Exploramos as principais convenções de nomenclatura:
- snake_case: Usado em Ruby, Python e C
- camelCase: Comum em JavaScript, Java e C#
- PascalCase: Para nomes de classes e módulos
- kebab-case: Para HTML, CSS e nomes de arquivos
Por fim, colocamos tudo em prática usando o IRB (Interactive Ruby) e criando um programa Ruby fora do IRB. Criamos variáveis, calculamos médias e verificamos aprovações usando booleanos, tanto no ambiente interativo quanto em um arquivo Ruby.
Dica: É possível observar que existem muitas coisas em inglês no código, como os nomes dos tipos de dados (Integer, Float, String, Boolean) e comandos (puts). Isso acontece porque a maioria das linguagens de programação foi criada em países de língua inglesa, então os termos técnicos e comandos são baseados nesse idioma. Mesmo programando em português, é comum usar esses termos em inglês, pois eles são universais na programação. Quanto mais código for lido e escrito, maior será a familiaridade (costume) com esses termos em inglês.
Na medida em que avançamos em nossa série de artigos vamos nos aprofundar mais em tipos de dados, variáveis e outros conceitos importantes da programação. De maneira gradual as coisas vão ficando mais claras e fáceis de entender.