
Computação para iniciantes

Apresentação
O mundo da tecnologia se expande como um cosmos em constante mutação, oferecendo um universo de oportunidades para aqueles que desejam desvendar seus segredos. Diferente de áreas como Direito e Medicina, que trilham caminhos mais lineares, a tecnologia se destaca por sua flexibilidade e por acolher profissionais de diversos perfis e formações. Este guia introdutório tem como objetivo apresentar os pilares da formação acadêmica necessária, as múltiplas vertentes de atuação profissional e os fundamentos técnicos que sustentam essa realidade em constante evolução.
No cerne dessa experiência está a máquina que dá vida à informação: o computador. Sua estrutura é dividida em dois reinos interligados: hardware e software. O hardware, reino físico e tangível, é composto por componentes como processadores, memórias, dispositivos de entrada e saída. Imagine o processador como o cérebro do computador, responsável pelo processamento das informações. Já as memórias, como fiéis escudeiros, armazenam dados e instruções. Através de teclados, mouses, monitores e impressoras, o hardware se conecta ao mundo exterior, capturando e exibindo informações.
Em contrapartida, o software reina no mundo intangível do código. Programas escritos em linguagens de programação ditam suas ações, como se fossem a linguagem natural da máquina. Sistemas operacionais, como Windows e Linux, assumem o papel de maestros, gerenciando os recursos do computador e permitindo a execução dos programas. Essa sinergia entre hardware e software é a essência da computação, possibilitando a realização de tarefas que vão desde as mais simples até as mais complexas.
Em um mundo cada vez mais conectado, as redes de computadores e a internet se erguem como pontes que interligam dispositivos e permitem a troca de informações em escala global. Imagine uma rede de computadores como uma comunidade vibrante, onde cada dispositivo contribui para o todo. Já a internet, a grande rede das redes, se assemelha a uma vasta teia que conecta pessoas, empresas e instituições de todo o planeta.
Através da World Wide Web (WWW), essa teia se torna acessível a todos por meio de navegadores, como portais de entrada para um universo infinito de informações. A criação de sites, utilizando linguagens como HTML, CSS e JavaScript, permite que cada indivíduo compartilhe suas ideias, produtos e serviços com o mundo. Essa interconexão global redefine a forma como nos comunicamos, aprendemos, trabalhamos e nos divertimos, tornando a informação acessível a um clique de distância.
É crucial salientar que a área de tecnologia se encontra em constante transformação, exigindo dos profissionais um compromisso com o aprendizado contínuo. Novas tecnologias surgem a cada dia, e a atualização constante de conhecimentos e habilidades é fundamental para se manter competitivo no mercado de trabalho.
Este guia introdutório tem como objetivo fornecer uma visão geral dos conceitos básicos da ciência da computação, abordando temas como estrutura do computador, programas, sistemas operacionais, redes de computadores, internet e desenvolvimento web. Ao final, são apresentadas referências para aprofundamento nos temas abordados.
É evidente que a tecnologia é um campo de possibilidades, e a jornada de cada pessoa é única. Além disso, o assunto é vasto e complexo, e este guia introdutório não o esgota. Ao contrário, é o ponto de partida para muitas descobertas e aprendizados.
Área de tecnologia

No Brasil, o ingresso em carreiras como Direito, Medicina e Engenharia se dá por meio de um roteiro bem definido: graduação na área específica, aprovação em exames profissionais (OAB, CRM, CREA, etc.) e cumprimento dos requisitos específicos de cada carreira. Essa estrutura garante um nível padronizado de conhecimento e habilidade entre os profissionais, assegurando a qualidade dos serviços prestados.
Por outro lado, a área de tecnologia se destaca por sua natureza dinâmica e em constante evolução, refletindo um panorama profissional mais flexível e diverso. As oportunidades para atuar nesse campo são amplas e abrangentes, desde o desenvolvimento de software e sistemas de informação até a gestão de redes e infraestrutura tecnológica.
Para compreender a amplitude e as nuances da tecnologia, é fundamental entender as ciências que a sustentam. Cada ciência possui um objeto de estudo específico: a Biologia explora os seres vivos e suas relações com o meio ambiente, enquanto a Física se dedica ao estudo dos fenômenos naturais. Essas áreas do conhecimento podem ser aplicadas a diferentes campos de atuação. A Biologia aplicada às pessoas dá origem à Medicina e Biomedicina, enquanto aplicada aos animais resulta em Medicina Veterinária e Zootecnia. Já a Física encontra aplicação em diversas engenharias, como Eletrônica e Mecânica.

A Ciência da Computação, por sua vez, se destaca por sua posição singular: ao mesmo tempo que se fundamenta em outras áreas do conhecimento, também serve como base para diversas outras. As raízes da Computação estão na Matemática, na Lógica, na Eletrônica, na Física e em outras áreas.
Para quem deseja se aprofundar na área de tecnologia, diversas opções de formação superior estão disponíveis. O bacharelado em Ciência da Computação oferece uma visão abrangente e generalista dos fundamentos da computação, incluindo métodos, ferramentas, técnicas e aplicações relacionadas ao computador, como protocolos de comunicação, algoritmos e teoria da computação. Essa graduação serve como base para diversas outras áreas com foco mais específico e aplicado.
Para quem se interessa pela parte física do computador, como placas, processadores, memórias, circuitos, programação de baixo nível e sistemas embarcados, a graduação em Engenharia da Computação é a opção ideal. Essa área se dedica ao projeto, desenvolvimento, implementação e operação de sistemas computacionais, com foco na otimização de desempenho e na eficiência energética.
Para quem se apaixona pela arte de ensinar, a licenciatura em Computação oferece a oportunidade de formar professores para o ensino de Informática e Computação. Essa graduação tem foco na área de educação, preparando profissionais para atuar como professores no ensino fundamental e médio, além de cursos técnicos e superiores. As bases são as mesmas da Ciência da Computação, mas com um foco mais direcionado para o ensino e a aprendizagem.
Se sua área de interesse é tecnologia da informação e negócios, com ênfase no desenvolvimento de sistemas de informação para empresas e organizações, a graduação em Sistemas de Informação é a escolha certa. O curso aborda temas como análise de sistemas, banco de dados, gestão de projetos, segurança da informação, entre outros. O objetivo é formar profissionais capazes de desenvolver sistemas de informação que atendam às necessidades das empresas e organizações, contribuindo para a melhoria dos processos e resultados.
Para quem se fascina pelo desenvolvimento de software, com ênfase em metodologias de desenvolvimento, qualidade de software, engenharia de requisitos, engenharia de software, entre outros, a graduação em Engenharia de Software é a opção ideal. Essa área se dedica ao projeto, desenvolvimento, implementação e manutenção de software de alta qualidade, que atenda às necessidades dos usuários e das empresas, e que contribua para a melhoria dos processos e resultados.
E para quem busca um curso de graduação com duração menor, em média de 2 a 3 anos, as graduações tecnológicas, ou tecnólogos, oferecem uma alternativa interessante. São cursos mais aprofundados em tópicos específicos dentro de uma área, com foco prático e ligados diretamente ao mercado de trabalho. Exemplos desses cursos são: Análise e Desenvolvimento de Sistemas, Banco de Dados, Gestão da Tecnologia da Informação, Redes de Computadores, Segurança da Informação, Sistemas para Internet, entre outros. O objetivo é lidar com o conhecimento e tecnologias que já estão disponíveis no mercado de trabalho, e que são utilizadas por empresas e organizações, com menor foco em pesquisa e desenvolvimento de novas tecnologias e conhecimentos, devido à menor duração do curso.

Como podemos observar, a área de tecnologia é um universo amplo e cheio de possibilidades, com diversas opções de graduações, cursos técnicos e a chance de migração de carreira. Essa flexibilidade permite que profissionais de diferentes áreas e formações ingressem no campo, impulsionando a diversidade de ideias e perspectivas. Isso significa que você não precisa necessariamente seguir um único caminho para alcançar o sucesso. É possível iniciar sua jornada em uma área específica e, posteriormente, migrar para outra, de acordo com seus interesses e habilidades.
Não existe nessa área um equivalente ao exame da OAB, ou ao CRM, ou ao Conselho de Engenharia, que sejam obrigatórios. Por isso, o perfil de profissionais de tecnologia é muito diversificado, existem pessoas que cursaram alguma graduação na área, pessoas que se formaram em outra área e migraram para a tecnologia, pessoas que não têm graduação e estudaram por conta própria, pessoas que fizeram cursos técnicos, além de mestres e doutores na área. A diversidade de perfis é muito alta, e a tecnologia é uma área que acolhe bem a diversidade, principalmente quando comparada a outros campos profissionais.
Essa flexibilidade, no entanto, não significa que a formação profissional seja irrelevante. Pelo contrário, investir em conhecimento e qualificação é crucial para se destacar nesse mercado dinâmico e competitivo. As graduações e cursos técnicos oferecem uma base sólida para o desenvolvimento de habilidades técnicas e teóricas, além de promover o networking (rede de contatos) com outros profissionais da área. No entanto, além da formação tradicional, existem diversas outras maneiras de adquirir conhecimento; a autoaprendizagem também é uma ótima opção para quem deseja se aprofundar em um tema específico ou desenvolver novas habilidades. O importante é entender que a tecnologia é uma área em constante evolução e que a busca pelo conhecimento é um processo contínuo e interminável.
No que diz respeito à atuação profissional, a tecnologia é uma área muito abrangente, com muitas possibilidades de atuação. Os perfis de empresas e cargos que alguém pode ocupar são variados. Algumas possibilidades incluem:
-
Empresas do setor público:
Os órgãos e empresas do setor público também desempenham suas atividades através de tecnologia. Portanto, é um meio em que se pode atuar, entretanto, é necessária uma graduação que varia de acordo com o órgão ou empresa, além de aprovação em concurso público. -
Empresas do setor privado:
Marcas como Nestlé, Coca-Cola e Grupo Boticário, que não são reconhecidas como empresas de tecnologia, também necessitam de profissionais da área graças ao backoffice. Este termo se refere à infraestrutura que permite a realização das atividades de departamentos como financeiro, marketing, pessoal, e atendimento ao cliente. Todas essas áreas possuem sistemas informatizados que precisam de profissionais qualificados. Por exemplo, a Nestlé, com seu gigantesco catálogo de produtos e atuação global, precisa estabelecer preços, regras de cada país, legislações, folhas de pagamento e fornecedores, e para tudo isso existem sistemas de backoffice. -
Empresas de tecnologia:
Estas são empresas focadas em produtos ou serviços tecnológicos, como Google, Apple, IBM, Microsoft, Oracle, Amazon, e Mercado Livre. O diferencial dessas empresas é que elas não apenas usam a tecnologia para funcionar, mas também para criar produtos e serviços. Se o sistema financeiro da Coca-Cola falhar, a empresa pode substituir por outro sistema e continuar vendendo refrigerantes. Já se o Google tiver um problema com o sistema de busca, a empresa para de funcionar, pois o produto dela é o sistema de busca. -
Empresas terceirizadas:
Essa categoria se subdivide em três subcategorias:-
Agências:
Fazem projetos simples como sites menores ou e-commerces de pequeno porte para pequenas empresas ou profissionais autônomos. -
Sistemas para freelancers:
Realizam projetos de curto prazo, como sites para festas de casamento ou sistemas de controle de estoque para pequenos comércios. Muitas vezes, esses projetos são feitos por uma única pessoa, sem equipe ou suporte. A remuneração é por projeto e pode variar muito de acordo com as taxas de cada plataforma. -
Empresas de consultoria:
Realizam projetos de médio e longo prazo, como sistemas de gestão de agências bancárias ou sistemas de controle de estoque para grandes indústrias. Essas consultorias podem ter equipes grandes, com profissionais de diferentes áreas e níveis de experiência, e a remuneração pode ser por hora de trabalho (CLT ou PJ), por projeto, ou por contrato.
Consultoria é um serviço prestado por uma empresa ou profissional a outra empresa ou pessoa, com a intenção de resolver um problema ou atingir um objetivo. Essas empresas muitas vezes são contratadas para resolver problemas de tecnologia, como a implementação de um novo sistema, a migração de um sistema antigo para um novo, a integração de sistemas diferentes, a otimização de um sistema existente, ou para trabalhar na área de tecnologia da informação da empresa contratante.
Isso é chamado de outsourcing de TI ou terceirização de TI e é uma prática comum no mercado. As empresas contratam consultorias quando não têm um time interno de tecnologia, quando o time interno existe mas precisa de reforço, ou quando o time interno não é especializado em um determinado assunto. As consultorias fornecem metodologia, experiência, conhecimento e alocam profissionais para trabalhar na empresa contratante.
-
Agências:

Em resumo, a área de tecnologia é um vasto campo de possibilidades, que acolhe e se adapta a profissionais de diferentes perfis e formações. A flexibilidade e a diversidade são marcas registradas desse universo em constante evolução, que oferece oportunidades para quem deseja desbravar seus segredos e desafios.
Estrutura básica do computador

Os computadores executam quatro funções distintas sendo elas: (a) Entrada; (b) Processamento; (c) Armazenamento e recuperação de dados; (d) Saída (MT Rebonatto. P. 6).
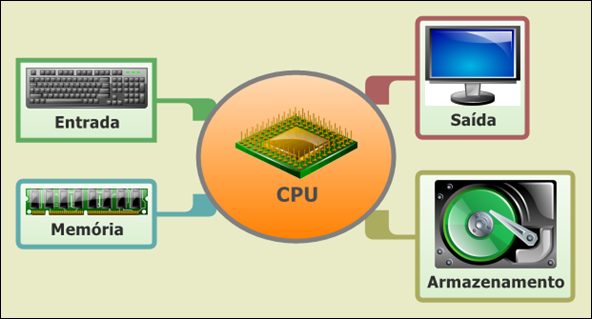
A imagem é um diagrama que representa os componentes principais de um computador e como eles estão conectados à CPU (Unidade Central de Processamento). No centro, há um círculo laranja com a palavra "CPU" e uma imagem de um chip de processador.
Quatro componentes estão conectados à CPU:
1. Entrada: Representada por um teclado, localizado no canto superior esquerdo.
2. Memória: Representada por módulos de memória RAM, localizada no canto inferior esquerdo.
3. Saída: Representada por um monitor, localizado no canto superior direito.
4. Armazenamento: Representado por um disco rígido, localizado no canto inferior direito.
Cada componente está ligado à CPU por uma linha colorida, indicando a conexão entre eles.
O computador é uma máquina que executa quatro funções básicas: entrada, processamento, armazenamento e saída. A entrada é a forma como o computador recebe informações, como o teclado, o mouse, a tela sensível ao toque, o microfone, a câmera, entre outros. O processamento é a forma como o computador executa tarefas, como a execução de programas, a realização de cálculos, a manipulação de arquivos, entre outros.
Para que um computador funcione, duas estruturas são necessárias: o hardware e o software. O hardware é a parte física do computador, como o teclado, o mouse, a tela, o processador, a memória, o disco rígido, a placa de vídeo, a placa de som, entre outros. O software é um componente lógico do computador, no qual não é possível tocar, mas que é essencial para o funcionamento do computador, como o Windows, o Word, o Excel, o PowerPoint, o Photoshop, o Chrome, o Firefox, o WhatsApp, o Facebook, o Instagram, entre outros.
A parte física do computador (hardware) precisa ter três elementos fundamentais são eles: os microprocessadores, as memórias e os dispositivos de entrada e saída.
Microprocessadores

Os microprocessadores podem ser comparados ao cérebro de um computador. Assim como o cérebro humano processa informações e toma decisões, o microprocessador realiza cálculos e executa instruções para que o computador funcione. Ele é um pequeno chip eletrônico que fica dentro do computador e é responsável por executar as operações mais básicas e essenciais.
Para entender como um microprocessador funciona, imagine uma calculadora muito rápida e eficiente. Quando você digita um número e pressiona uma tecla de operação, como “somar” ou “multiplicar”, o microprocessador realiza essa operação em uma fração de segundo. Além de cálculos matemáticos, ele também realiza outras tarefas, como mover dados entre diferentes partes do computador e controlar periféricos como o teclado e o monitor.
Memórias
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/a/j/9sD2tLSlSGROwj0IJ6AA/2013-12-22-memoria-ram.jpeg)
As memórias em um computador são como blocos de anotações onde as informações são armazenadas. Existem dois tipos principais de memórias: voláteis e não voláteis.
A memória volátil, ou RAM (Random Access Memory ou Memória de Acesso Aleatório), pode ser comparada a um quadro branco. Quando você escreve algo no quadro branco, pode usar essas informações enquanto o quadro está visível. No entanto, quando apaga o quadro ou desliga as luzes da sala, todas as anotações desaparecem. Da mesma forma, a RAM armazena informações temporariamente enquanto o computador está ligado. Quando você desliga o computador, todas as informações na RAM são perdidas.
Um exemplo cotidiano de RAM é o uso de um aplicativo de edição de texto. Quando você está escrevendo um documento, as informações são armazenadas na RAM, permitindo acesso rápido e fácil às mudanças que você faz. Mas se você não salvar o documento antes de desligar o computador, tudo o que foi escrito será perdido.
A memória não volátil, por outro lado, armazena informações de forma permanente, mesmo quando o computador está desligado. Os discos rígidos (HDs) e as unidades de estado sólido (SSDs) são exemplos de memórias não voláteis. Elas funcionam como um caderno onde você escreve informações importantes que precisam ser guardadas por muito tempo.
Um exemplo prático é o armazenamento de fotos no seu celular. Quando você tira uma foto, ela é salva na memória não volátil do celular. Mesmo que você desligue o aparelho, as fotos permanecem lá e podem ser acessadas a qualquer momento.
A memória é um conjunto de células, todas com o mesmo número de bits, sendo cada célula identificada por um número único que é seu endereço. Os acessos à memória são realizados através de palavras de memória, sendo que a velocidade da memória, indicada pelo seu tempo de acesso, é significativamente inferior à velocidade com que o processador trabalha (MT Rebonatto. P. 8).
Rebonatto descreve a memória do computador como um conjunto de células, ou como um “grande rolo de células”. Para quem conhece a escrita Braille (usada por pessoas cegas ou com baixa visão), essas células de memória podem ser comparadas às células Braille da reglete. A reglete é um instrumento usado para escrever em Braille e se parece com uma régua com pequenos quadradinhos, chamados de células Braille. Cada uma dessas células pode guardar apenas uma letra, ou seja, um quadradinho para cada letra.
Pode-se dizer que cada letra em uma célula Braille tem um endereço único, que é a posição desse quadradinho na reglete. Da mesma forma, no computador, as células de memória têm um “endereço” numérico, o que permite escrever dados em uma de suas posições. Pense nas posições das células de memória como cada quadradinho na reglete do Braille; é assim que se torna possível ler os dados.


Ou seja, a variável "a" está na posição 1000, a variável "q" está na posição 1004, a variável "y" está na posição 1008, "m" está na posição 1012, "c" está na posição 1016, "p" está na posição 1020, "r" está na posição 1024, "z" está na posição 1028. O nome da variável é o que a pessoa programadora usa para se referir a ela, o endereço de memória é o que o computador usa para se referir a ela. Ambos apontam para a mesma posição na memória que vai guardar algum conteúdo como os quadradinhos da reglete Braille guardam letras.
Dispositivos de entrada e saída
Os dispositivos de entrada e saída determinam como o computador captura informações do ambiente externo e como ele devolve essas informações. Entrada é a forma como o computador recebe informações, enquanto saída é a forma como ele devolve essas informações.
Teclados, mouses, scanners, microfones e câmeras são dispositivos de entrada. Eles permitem que a pessoa insira informações no computador, como texto, imagens, sons e vídeos.
Monitores, impressoras, caixas de som, fones de ouvido e projetores são dispositivos de saída. Eles permitem que o computador devolva informações para a pessoa, como texto, imagens, sons e vídeos. Além disso, existem dispositivos que funcionam como a entrada e a saída ao mesmo tempo, como as telas sensíveis ao toque, os modems e as placas de rede.
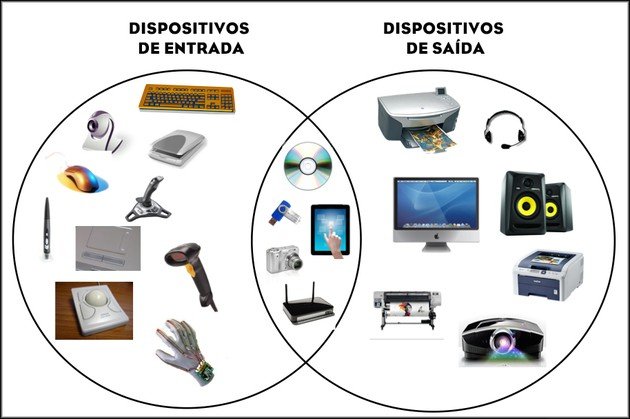
A imagem é um diagrama de Venn que classifica dispositivos de entrada e saída de um computador. O diagrama é dividido em duas seções principais: "Dispositivos de Entrada" à esquerda e "Dispositivos de Saída" à direita.
Na seção "Dispositivos de Entrada", estão os seguintes itens:
- Teclado
- Mouse
- Scanner
- Microfone
- Câmera digital
- Caneta digitalizadora
- Joystick
- Mesa digitalizadora
- Leitor de código de barras
- Trackball
- Luva de dados
Na seção "Dispositivos de Saída", estão os seguintes itens:
- Impressora
- Monitor
- Fone de ouvido
- Alto-falante
- Projetor
- Plotter
- gravador de CD/DVD
No centro, onde as duas seções se sobrepõem, está um roteador, que pode ser considerado tanto um dispositivo de entrada quanto de saída.
Programas ou Softwares

Primeiramente, é importante entender que programas de computador, ou softwares, são como receitas de culinária que precisamos seguir passo a passo. Imagine que você está preparando um bolo: você precisa de uma receita que liste todos os ingredientes e explique cada etapa do preparo, desde misturar a massa até assar no forno. Da mesma forma, um programa de computador precisa de uma “receita” que diz ao computador exatamente o que fazer.
Essas “receitas” que os computadores seguem são chamadas de algoritmos. Um algoritmo é uma sequência de instruções lógicas que descreve os passos necessários para realizar uma tarefa específica. Por exemplo, um algoritmo pode ser usado para ordenar uma lista de números ou para calcular a soma de dois valores.
Os algoritmos são escritos em diferentes linguagens de programação, que são como idiomas que os computadores entendem. Cada linguagem de programação tem suas próprias regras e sintaxe, assim como cada idioma tem sua gramática e vocabulário.
Um programa nada mais é que um tipo de algoritmo. Sua particularidade é que suas operações são específicas para o computador e restritas ao que o processador pode executar (M Medina, C Ferlig. São Paulo. Novatec Editora. 2005, p. 15).
Um programa é uma categoria específica de algoritmos. Em outras palavras, é um conjunto de instruções que descreve uma atividade a ser realizada. Essas instruções são adaptadas para as capacidades do processador do computador. Essas adaptações são essenciais porque os processadores não conseguem entender as linguagens humanas, que são complexas e ambíguas. O processador só entende números.
Para quem vê imagens na tela do computador, ouve músicas, escreve textos, joga ou realiza diversas atividades, pode parecer difícil acreditar que o computador não entende nada daquilo que está sendo mostrado, tocado ou impresso. Na verdade, o computador não entende o que é uma música ou uma imagem. Ele não sabe a diferença entre uma guitarra e uma bateria, nem sabe se uma foto é de um casamento, uma formatura ou de uma casa. Para o computador, tudo isso é representado por números binários, ou seja, sequências de zeros e uns.
Para entender como isso funciona, podemos comparar com o corpo humano. Nossos olhos, por exemplo, captam imagens, mas não as interpretam. Eles enviam essas imagens ao cérebro, que é quem faz a interpretação. Existem pessoas cegas que têm comprometimentos não nos olhos, mas em outras partes do sistema visual, como o nervo óptico ou o córtex. Os olhos são apenas receptores de informação visual; é o cérebro que interpreta essas imagens.
O computador é uma máquina elétrica e tudo nele se resume a passar ou não corrente elétrica. A matemática é usada para representar e manipular esses números no nível mais básico. É por isso que dizemos que o computador só entende números binários: 0 e 1, onde 0 significa que não há corrente elétrica passando e 1 significa que há corrente elétrica passando.
Agora, você pode estar se perguntando: “Se o computador só entende 0 e 1, como é que eu vejo fotos e vídeos e faço tantas coisas com ele?” A resposta é que, assim como o corpo humano usa abstrações para interpretar o mundo ao seu redor, o computador usa camadas de abstração para converter números binários em imagens, sons e outras formas de informação.
No corpo humano, tudo começa com impulsos elétricos, químicos e hormônios. Essas reações básicas são interpretadas pelo cérebro, que então nos permite perceber e entender o mundo. De maneira semelhante, o computador usa linguagens de programação como uma forma intermediária para converter números binários em comandos que ele pode executar. Essas linguagens têm regras gramaticais e um vocabulário limitado de palavras-chave que organizam as instruções.
Existem muitas linguagens de programação, assim como existem muitos idiomas humanos. Cada linguagem de programação tem suas próprias regras e é usada para escrever programas específicos que o computador pode entender e executar.
De acordo com M Medina e C Ferlig (2005), “A linguagem de programação que um computador é capaz de compreender é composta apenas de números.”
Por isso, as linguagens de programação são classificadas em níveis, de acordo com sua semelhança com a linguagem humana. Existem três níveis principais: linguagens de máquina, linguagens de baixo nível e linguagens de alto nível.
As linguagens de máquina são entendidas diretamente pelo computador, com instruções representadas por valores binários (0 ou 1), chamados de bits. As linguagens de baixo nível são mais próximas da linguagem de máquina, mas já podem ser entendidas por seres humanos.
Por isso, para facilitar a programação de computadores foi necessária a criação de um código que relacionasse a linguagem de máquina a uma linguagem mais fácil de ser compreendida. A linguagem de montagem (ou Assembly) (M Medina, C Ferlig. São Paulo. Novatec Editora. 2005. P. 15).
Assembly é conhecida como linguagem de montagem e, às vezes, chamada de linguagem simbólica. Embora não seja uma linguagem nativa do processador, ela mantém elementos da linguagem de máquina que exigem que a pessoa programadora conheça a arquitetura do computador. Assembly tem a mesma organização e conjunto de instruções da linguagem de máquina, mas permite que quem programe use nomes (mnemônicos) e símbolos em vez de números.
Os programas desenvolvidos em Assembly levam em conta a arquitetura da Unidade Central de Processamento (UCP), então um programa pode não funcionar em arquiteturas diferentes da qual foi projetado. É importante não confundir Assembly com Assembler: Assembly é a linguagem de montagem, enquanto Assembler é o programa que traduz códigos de Assembly para a linguagem de máquina.
Para aumentar a produtividade dos programadores e a portabilidade dos programas, foram criadas as linguagens de programação de alto nível. Essas linguagens são independentes do processador em que serão executadas (M Medina, C Ferlig. São Paulo. Novatec Editora. 2005. P. 17).
As linguagens de alto nível são mais próximas da linguagem humana, permitindo programar usando palavras e símbolos de forma mais intuitiva, como se estivesse escrevendo um texto. No entanto, programas escritos em linguagens de alto nível não são executados diretamente pelo computador; eles precisam ser “traduzidos” para código de máquina. Essa conversão é feita por intermediários chamados compiladores ou interpretadores.
Para que uma linguagem de programação crie um programa de fato, é necessário que as instruções (algoritmos) sejam salvas em arquivos chamados de código-fonte. Esse código-fonte precisa ser convertido para linguagem de máquina através de um processo chamado compilação, ou interpretado em tempo real através de um processo chamado interpretação.
A compilação traduz todo o código-fonte em um ou mais arquivos que podem ser armazenados e executados quantas vezes for necessário, sem precisar traduzir novamente a cada execução. Isso é feito pelo compilador. A interpretação, por outro lado, executa os comandos do código-fonte à medida que os traduz, ou seja, a interpretação ocorre em tempo real. Cada vez que o programa for executado, será necessário interpretá-lo novamente. Esse processo é feito pelo interpretador, e a grande vantagem é a possibilidade de executar o programa independentemente da arquitetura da máquina ou do sistema operacional (Windows, Linux ou Mac).
Sistemas operacionais

Há dois modos diferentes de conceituar um sistema operacional: o top-down, como uma abstração do hardware, fazendo o papel de intermediário; Além do bottom-up, como um gerenciador de recursos que controla qual aplicação pode ser executada, quando será executada e quais recursos podem ser utilizados (Silberschatz et al, 2005; Stallings, 2004; Tanenbaum, 1999).
O Sistema Operacional (SO) é um tipo de programa que ajuda a controlar o computador e outros programas usados por pessoas. Ele funciona como uma base que administra os recursos do computador e permite que outros programas rodem por cima dele.
Antes dos sistemas operacionais, os computadores precisavam de muita intervenção humana para funcionar. Isso começou a mudar na década de 1960, quando desenvolvedores da AT&T Bell Labs criaram um software mais fácil de usar. Em 1969, eles lançaram o UNIX, o primeiro sistema operacional proprietário.
Depois disso, surgiram muitos outros sistemas operacionais, como o BSD em 1977, Apple DOS em 1978, Apple SOS em 1980 e MS-DOS em 1981. O MS-DOS, por exemplo, era usado nos computadores da IBM e permitia o uso de discos rígidos de 10 MB e organização de arquivos em formato de "árvore". Com o tempo, ele recebeu suporte para redes e o sistema de arquivos FAT16, tornando-se a base para o Windows.
Outro sistema importante foi o MINIX, criado por Andrew S. Tanenbaum, que inspirou Linus Torvalds a desenvolver o Linux em 1991. O Linux é especial porque é de código aberto, permitindo que qualquer programador o modifique, resultando em muitas versões gratuitas adaptadas para diferentes necessidades.
O Windows, por sua vez, começou com o MS-DOS e ficou famoso em 1995 com o lançamento do Windows 95. Ele introduziu o Menu Iniciar e a barra de tarefas, usados até hoje. A versão XP, lançada em 2001, foi uma das mais populares e ajudou a Microsoft a se destacar entre os usuários comuns.
Em resumo, um sistema operacional coordena processos, gerencia a memória, controla o hardware, permite a conexão em redes e oferece segurança nas operações de entrada e saída de dados.
O sistema operacional é uma camada de software que opera entre o hardware e os programas aplicativos voltados ao usuário final. O sistema operacional é uma estrutura de software ampla, muitas vezes complexa que incorpora aspectos de baixo nível (como drivers de dispositivos e gerência de memória física) e de alto nível (como programas utilitários e a própria interface gráfica) (C. A. Maziero. 2014. P. 11).
O sistema operacional faz parecer que várias tarefas estão acontecendo ao mesmo tempo no computador, mas na verdade, ele divide essas tarefas em processos. Cada processo recebe um pouco do tempo do processador, e a troca entre eles é tão rápida que parece que estão rodando ao mesmo tempo.
Os sistemas operacionais representam os componentes físicos do computador para que possam ser usados corretamente. Para que um computador funcione, é necessária uma interface para o usuário. As interfaces mais comuns são: terminal, textual e gráfica. A interface de terminal, também chamada de CLI (Command Line Interface), funciona só com o teclado, onde os comandos são digitados e lidos por um interpretador de comandos, ou shell.
Há também a interface textual, que funciona com texto, mas possui menus, janelas e botões. Era popular em sistemas baseados no MS-DOS, como o DOS Shell, mas hoje em dia é rara, usada apenas em aplicações antigas dos anos 80 e início dos 90.
A GUI (Graphical User Interface) tem menus, janelas e botões, além de figuras e áreas de texto. Nela, o usuário interage com o mouse, teclado ou toques em telas sensíveis. Isso facilita o uso, eliminando a necessidade de comandos e prompts para usuários comuns.
Um sistema operacional tem partes voltadas para o usuário e partes para o funcionamento do computador. Quando se fala de Windows, Linux ou Mac OS, as pessoas geralmente lembram da interface gráfica e da usabilidade. Porém, um sistema operacional também inclui um sistema de arquivos e o kernel.
O kernel é o núcleo do sistema operacional. Ele se conecta com a linguagem de máquina e o hardware, reconhece e inicia os componentes ao ligar o computador, gerencia o processador, a RAM e os dispositivos de entrada e saída. Além disso, o kernel gerencia a execução de programas, controla o uso de dispositivos, a memória do sistema e as chamadas de programas, decidindo quais têm prioridade.
Entender o sistema operacional como um software complexo que vai além do que se vê é importante. Sem esse conhecimento, a diferença entre sistemas como Mac OS, Windows e Linux fica restrita à interface gráfica. Simplificar tudo pela aparência é aceitável para usuários comuns, mas uma pessoa desenvolvedora de software deve entender essas questões, mesmo que minimamente.
Windows, Linux e Mac OS
Agora que entendemos o que é um sistema operacional, como ele funciona e suas partes principais, vamos ver as diferenças importantes entre Windows, Linux e Mac OS.
Primeiro, é importante saber que Windows e Mac OS são produtos de empresas privadas. O Windows é da Microsoft e o Mac OS é da Apple. Já o Linux não é um sistema completo; ele é apenas o kernel, que é a parte do sistema que inicia a máquina e verifica o hardware.
O Microsoft Windows é tão comum que muitas pessoas pensam nele como sendo o próprio computador. Para a maioria das pessoas, usar um computador é o mesmo que usar o Windows, instalando programas como o Word e o Google Chrome. Por isso, muitos nem percebem que estão usando um sistema operacional, eles acham que o Windows é o próprio computador.
Não vamos entrar na história da Microsoft ou nas várias versões do Windows, mas aqui estão alguns pontos importantes. O Windows é na verdade uma família de sistemas operacionais, incluindo Windows 10, Windows 11 e Windows Server. O Windows tem uma interface gráfica e uma maneira específica de fazer as coisas, porque a Microsoft define tudo sobre como o Windows funciona. Isso faz com que as pessoas pensem que a maneira de usar um computador é como se faz no Windows. Quando essas pessoas compram um Mac, precisam aprender como fazer as mesmas coisas de um jeito diferente.
Para entender melhor, pense em carros da Chevrolet e da Volkswagen. As pessoas comparam o Windows e o Mac OS como se fossem carros de marcas diferentes. Elas pensam que a única diferença é a marca, mas na verdade, cada sistema operacional é feito de um jeito diferente, assim como os carros são fabricados de maneiras diferentes.
O Linux é diferente. Ele não é um sistema operacional completo como o Windows ou o Mac OS. O Linux é apenas o kernel, que faz a comunicação entre os programas e o hardware. Outras partes do sistema operacional, como a interface gráfica e o sistema de arquivos, não vêm com o Linux. Isso significa que qualquer pessoa pode usar o kernel Linux para criar seu próprio sistema operacional.
Por exemplo, o Ubuntu é uma distribuição Linux, administrada pela empresa Canonical. Ele é um sistema operacional completo que usa o kernel Linux, o gerenciador de arquivos Nautilus e a interface gráfica Gnome. Outro exemplo é o Linux Mint, que também usa o kernel Linux, mas tem seu próprio gerenciador de arquivos e interface gráfica.
Existem muitas distribuições Linux, como Fedora e SUSE, e cada uma escolhe as partes que quer usar, criando sistemas operacionais diferentes. A única coisa que todas têm em comum é o kernel Linux.
As diferenças entre Windows, Mac OS e as distribuições Linux vão além da aparência. Cada sistema tem sua própria maneira de gerenciar tarefas, programas e recursos do computador, como processador e memória. Essas diferenças são importantes para desenvolvedores de software, mas para usuários comuns, a aparência e a forma de uso são o que mais se nota.
Para quem trabalha com tecnologia, especialmente com desenvolvimento de software, é bom conhecer um pouco de cada sistema operacional, em vez de escolher um lado como se fossem times de futebol.
O que é a internet? Como ela funciona?

Quando pensamos em um canal de TV ou estação de rádio, é fácil entender como a informação chega até nossos aparelhos de TV e rádio. Primeiro, um programa é produzido (como uma reportagem ou novela), depois é transmitido pelas emissoras de TV e rádio. O sinal dessas emissoras é captado pelas antenas dos aparelhos e, assim, vemos o vídeo na TV ou ouvimos o som no rádio.
Mas quando o assunto é a internet, o caminho que a informação percorre não é tão conhecido pelo público. As pessoas usam notebooks, computadores, smartphones, tablets e outros dispositivos, mas não sabem como a informação chega até eles. Assistir a vídeos, acessar redes sociais, ler livros digitais e outras atividades parecem simples porque a infraestrutura por trás dos sites e aplicativos é desconhecida.
Onde ficam armazenados os vídeos do YouTube, as séries da Netflix e as fotos do Instagram? O que é a internet afinal?
Imagine uma biblioteca enorme, com livros organizados em prateleiras de várias categorias, como autor, assunto, quantidade de páginas, etc. Para encontrar um livro, a pessoa precisa saber onde ele está na biblioteca, ir até a prateleira certa e procurar.
A internet funciona de maneira semelhante. Ela é como uma grande biblioteca mundial com infinitos assuntos. Embora existam sites muito conhecidos, há um oceano de outros sites, aplicativos e conteúdos para explorar. Nesse cenário, existem duas figuras importantes: clientes e servidores, que muitas vezes são desconhecidas pelo público geral.
Pense nos clientes como visitantes curiosos, cada um com uma pergunta ou pedido (como acessar o Google ou Instagram). Esses clientes podem ser seus computadores, tablets ou smartphones – qualquer coisa que você usa para se conectar à internet. Os servidores, por outro lado, são como a cozinha de um restaurante. Os dispositivos (clientes) fazem o pedido e o servidor é onde toda a "comida" (informação) é armazenada e preparada. Na internet, quando você usa um site ou aplicativo, é o servidor que fornece as informações ou serviços, assim como a cozinha prepara a comida no restaurante.
Os dispositivos dos clientes são computadores, notebooks, smartphones, tablets, etc. Mas o que são os servidores? Servidores são computadores também, mas muito maiores e preparados para oferecer serviços e suportar um grande número de acessos ao mesmo tempo. Assim como um caminhão grande pode transportar muitos sacos de cimento, um servidor pode lidar com muitas solicitações ao mesmo tempo.
Um servidor é um grande computador que, junto com outros servidores, fornece todos os sites que acessamos. Esses servidores ficam em lugares chamados Data Centers. Empresas como Google, Microsoft e Meta (ex-Facebook) têm seus próprios Data Centers com servidores espalhados pelo mundo para manter seus serviços funcionando 24 horas por dia, 7 dias por semana.
Existem também empresas que não possuem Data Centers, mas alugam esses serviços de outras, como a Amazon, que mantém Data Centers próprios e também aluga para outras empresas. Antigamente, grandes corporações precisavam ter seus próprios Data Centers para suas operações, como bancos. Hoje, muitas empresas preferem alugar servidores de provedores como Amazon, Google e Microsoft.
Por exemplo, a Receita Federal do Brasil não precisa de grandes Data Centers operando em capacidade máxima o ano todo, mas durante o período de declaração do imposto de renda, ela precisa. Para evitar que o sistema saia do ar devido ao grande volume de acessos, a Receita pode alugar servidores da Amazon ou de outras empresas durante esse período. TikTok, iFood e Itaú Unibanco podem ou não ter seus próprios servidores, mas para estarem disponíveis na internet, precisam estar hospedados em algum servidor, alugado ou próprio.
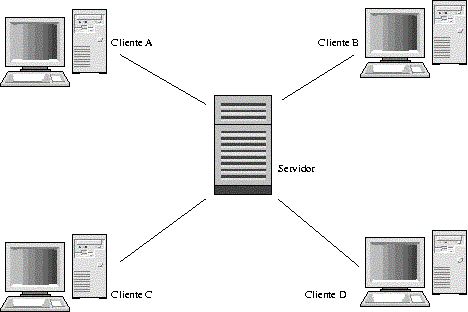
A imagem mostra um diagrama de rede de computadores. No centro, há um servidor representado por uma torre de computador com várias linhas horizontais. Quatro linhas saem do servidor, cada uma conectando a um cliente (computador) em cada canto da imagem.
Os clientes são identificados como:
- Cliente A (canto superior esquerdo)
- Cliente B (canto superior direito)
- Cliente C (canto inferior esquerdo)
- Cliente D (canto inferior direito)
Cada cliente é representado por um monitor e uma torre de computador.
Como os computadores se comunicam na internet?
Até aqui, entendemos que a internet é como uma biblioteca mundial de informações onde as pessoas buscam o que precisam. Quando acessam um site ou serviço, seus dispositivos se conectam com servidores que estão em Data Centers para obter os dados. Mas com tantos clientes e servidores, como os computadores se encontram? Como eles conseguem achar e trazer o que a pessoa deseja?
Todo computador conectado à internet possui um endereço único chamado IP (Internet Protocol). O endereço IP funciona de forma semelhante ao CEP. Com o CEP e o número da casa, os correios e transportadoras conseguem entregar encomendas. Da mesma forma, através do IP, o computador cliente localiza o servidor e vice-versa.
Exemplo de endereço IP:
https://192.168.0.1
Ao observar o endereço IP, é possível que muitas pessoas se perguntem:
Mas, quando entro na internet não coloco nenhuma sequência de números, eu busco por https://www.qualquer-site.com.br e o site abre para mim...
Isso é verdade e acontece porque existe algo na internet chamado domínio, os domínios são os nomes dos sites propriamente ditos como google, Instagram, youtube e afins, são esses domínios que são pesquisados e não números. Então o que acontece? Como esses nomes viram uma sequência de números para serem encontrados?
Existe um serviço chamado Sistema de Nomes de Domínio ou em inglês Domain Name System, conhecido apenas como DNS, é o DNS quem “traduz” o domínio pesquisado para o endereço IP de um site.
Sabe o WhatsApp, ou Telegram? Quando alguém busca por um contato, para iniciar uma conversa, pesquisa pelo nome, mas o aplicativo associa o nome do contato a um número (o registrado pela pessoa quando criou a conta). Então o que o WhatsApp faz é converter um nome para um número e assim proporcionar a conversa entre os dois contatos, o DNS atua da mesma maneira convertendo domínios de sites e serviços para seus endereços IP na rede.
/i588760.jpeg)
A imagem é um diagrama que ilustra o funcionamento de uma consulta DNS (Domain Name System). À esquerda, há um ícone de um laptop. À direita, há um ícone que representa um servidor DNS.
O diagrama mostra duas setas:
- Uma seta saindo do laptop em direção ao servidor DNS com o texto "www.google.com".
- Outra seta retornando do servidor DNS para o laptop com o texto "216.58.217.46".
Isso demonstra que o laptop envia uma solicitação ao servidor DNS para resolver o nome de domínio "www.google.com" e o servidor DNS responde com o endereço IP "216.58.217.46".
Protocolos de comunicação
Um protocolo nada mais é do que um acordo, uma convenção sobre como determinada ação será executada, um exemplo bem simples: é protocolo obrigatório na área de saúde lavar as mãos antes de qualquer procedimento. Os idiomas pelos quais as pessoas se comunicam também possuem protocolos, para construir palavras, frases e até mesmo abreviações. A maneira de se estruturar esses elementos é diferente no Inglês, português, francês, Italiano e afins.
Na internet também existem protocolos de comunicação na arquitetura cliente-servidor, para entender melhor pense que até agora o seguinte fluxo sobre o acesso a sites e aplicativos foi explicado:
- O dispositivo cliente solicita as informações.
- O servidor processa a solicitação.
- O servidor responde a solicitação.
- Cliente recebe a resposta com as informações solicitadas.
Mas como essa comunicação acontece? Como o dispositivo do cliente entende o servidor e vice-versa? Essa comunicação acontece através de protocolos, assim como os idiomas. No caso da internet, usamos os protocolos HTTP (Hypertext Transfer Protocol), por isso todo endereço de site começa com http ou https. No endereço:
https://www.meu-site.com.br
-
http
Faz referência ao protocolo de comunicação usado.
-
s
Faz referência a security (ou segurança) para indicar que é um acesso seguro com criptografia.
-
://
Serve para separar o protocolo usado (nesse caso o https) do restante da URL, indicando o que é informação do protocolo e o que é do endereço do site ou serviço em si.
-
www.
Faz referência a World Wide Web, em português rede mundial de computadores.
-
meu-site
É o nome do site ou serviço que se deseja acessar. É o domínio que será convertido para um endereço IP pelo DNS na hora de buscar o servidor.
-
.com.br
É a extensão do domínio, no caso .com.br é uma extensão de domínio brasileira. Existem várias extensões de domínio, como .com, .org, .net, .gov, e afins. Cada extensão tem um significado e um uso específico. A extensão .com é a mais comum e é usada por empresas comerciais, a .org é usada por organizações sem fins lucrativos, a .net é usada por empresas de tecnologia e a .gov é usada por governos. Existem muitas outras extensões de domínio, cada uma com seu uso específico.
A extensão .br é a extensão de domínio do Brasil, e é usada por empresas brasileiras. Então um site com a extensão .com.br é um site de uma empresa com finalidade comercial no Brasil.
Então o endereço https://www.meu-site.com.br é uma URL que quer dizer: acesse através do protocolo HTTP via comunicação segura da World Wide Web meu-site com finalidade comercial de origem no Brasil.
Além do HTTP, existem outros protocolos de comunicação na internet, como o FTP (File Transfer Protocol), que é usado para transferir arquivos entre computadores, o SMTP (Simple Mail Transfer Protocol), que é usado para enviar e-mails, e o POP3 (Post Office Protocol 3), que é usado para receber e-mails.
Desta forma acontece a comunicação entre cliente e servidor, claro que se trata de um resumo, mas é uma forma de entender como a internet funciona.
Navegadores Web
Para acessar sites e serviços na internet, é necessário um navegador web. O navegador é um programa que permite acessar a internet e visualizar páginas da web. Ele interpreta o conteúdo dos sites e exibe para a pessoa, permitindo a interação com o site ou serviço.
Existem vários navegadores web disponíveis, como Google Chrome, Mozilla Firefox, Microsoft Edge, Safari e Opera. Cada navegador tem suas próprias características e funcionalidades, mas todos têm em comum a capacidade de acessar sites e serviços na internet.
No baixo nível, os navegadores web são programas que se comunicam com servidores de sites e serviços, solicitando e recebendo informações para exibir na tela. Eles interpretam o código HTML, CSS e JavaScript (que serão explicados mais adiante) dos sites e serviços, transformando em páginas visualmente atraentes e interativas. Além disso, os navegadores web também se comunicam com outros programas, como plugins e extensões, para fornecer funcionalidades adicionais as pessoas.
Como softwares são feitos?

Através da lógica de programação e das linguagens de programação, é possível criar e executar programas de computador. Mas, como esses programas são organizados e divididos? Como é possível criar softwares complexos, como aplicativos de celular, sites e sistemas? Como tudo isso é feito? Para responder a essas perguntas, é necessário entender a diferença entre back-end e front-end.
No passado os sistemas eram mais simples e por isso não era incomum que o programa inteiro fosse desenvolvido por uma única pessoa. Além disso, os computadores eram muito mais restritos, não havia a possibilidade de alguém ter um computador em casa, foi somente a partir dos anos 80 que isso se tornou possível, nos anos 90 se expandiu e a partir dos anos 2000 se tornou comum. Com a popularização dos computadores e a Internet a quantidade de pessoas que usam software aumentou e eles precisaram ficar mais complexos.
Como funcionava antes? As empresas compravam computadores e instalavam softwares com disquetes, CDs e DVDs, os softwares eram instalados e atualizados manualmente, o que era um processo lento e caro. As mídias físicas eram compradas de uma Microsoft, IBM, Oracle, SAP e afins, e a empresa precisava de um técnico para instalar e configurar o software.
Depois desse processo, o software era utilizado e ficava assim por anos (ou até décadas), com atualizações esporádicas. O software era feito para durar, era caro e difícil de ser substituído. Com a popularização da Internet, a situação mudou.
A popularização da Internet trouxe consigo uma série de mudanças no mundo do software, a começar pela forma como ele é distribuído. Hoje em dia, praticamente não se usa mais mídias físicas para instalar softwares, tudo é feito pela Internet. A Microsoft, por exemplo, não vende mais o Windows em caixinhas, ele é baixado da Internet e ativado com uma chave de licença. O mesmo vale para os softwares da Adobe, da Autodesk, da Oracle e de muitas outras empresas.
Outra revolução que a Internet trouxe foram novas formas de interação com o software. Sites, aplicativos, redes sociais, jogos online, streaming de música e de vídeo e muitas outras coisas que antes eram impensáveis se tornaram comuns. Hoje em dia, é possível fazer quase tudo pela Internet, desde comprar um carro até assistir aulas de uma universidade estrangeira.
Então temos os seguintes fatores:
- Mudanças em contexto de software muito, muito mais rápidas.
- Número gigante de pessoas usuárias de software.
- Capacidade das pessoas criarem conteúdo nos softwares.
- Novas categorias de hardware e software (exemplo: smartphones e aplicações web).
É de se supor que não seria possível produzir e manter softwares da mesma maneira que se fazia nos anos 80 e 90, de fato não é mais assim que as coisas funcionam hoje. Tudo se tornou tão complexo que o software foi dividido em partes, partes essas nas quais são possíveis carreiras inteiras.
Essas partes são chamadas de front-end e back-end e serão explicadas a seguir.
Front-end é a parte do software que interage diretamente com as pessoas usuárias. É a interface gráfica, o que as pessoas veem e interagem. O front-end é responsável por exibir informações, receber comandos e enviar dados para o back-end. É o front-end que faz o software ser bonito, fácil de usar e agradável de interagir.
A construção do front-end envolve mais etapas e profissionais do que se imagina, é um trabalho que envolve design, programação e testes. Imagine o seguinte cenário: Através do time de produtos em um banco, foi decidido que o aplicativo de celular do banco precisa ser modernizado, a interface precisa ser mais amigável, mais bonita e a navegação mais intuitiva.
A partir disso, o time de produtos passa a demanda para o time de tecnologia, que recebe a tarefa, com seus requisitos e prazos, de modernizar o aplicativo. Então, serão feitas perguntas, como as listadas a seguir.
-
O time de design vai perguntar:
- Ok, as pesquisas do time de produtos indicam que os clientes não estão satisfeitos com a interface atual, isso acontece principalmente na tela de login, pix e transferências. O que essas telas tem em comum que pode estar causando insatisfação?
- Na modernização do aplicativo, que pontos da interface devem receber mais atenção para agradar aos clientes? Sobretudo nas telas que geraram mais reclamações.
- Como será desenhada a nova experiência do usuário? Quais elementos de UI e UX serão usados para tornar a navegação mais intuitiva?
- Como ficarão as cores, fontes, botões e ícones do aplicativo? A identidade da marca será mantida ou será feita uma reformulação?
- Conclusão: Depois que essas e outras perguntas forem respondidas, o time de design vai criar os protótipos das telas, protótipos são representações visuais do fluxo de telas do aplicativo, eles são usados para validar a experiência do usuário antes de serem construídas. Essa prototipação é feita em ferramentas como Figma (a mais usada), Adobe XD, Sketch e afins.
-
O time de programação front-end vai perguntar:
- Com o protótipo em mãos, o time de programação front-end vai perguntar o que é necessário para transformar o protótipo em código.
- Quais tecnologias serão usadas para desenvolver o front-end do aplicativo? Será usado React Native (que é uma tecnologia híbrida), Flutter (que é uma tecnologia híbrida), Swift (que é uma tecnologia nativa para iOS), Kotlin (que é uma tecnologia nativa para Android) ou outra tecnologia?
- Como será a arquitetura do front-end? Será usado um padrão de arquitetura como MVC (Model-View-Controller), MVVM (Model-View-ViewModel), MVP (Model-View-Presenter), ou será feita uma arquitetura personalizada?
- Como será a integração com o back-end? Será usado REST (Representational State Transfer), GraphQL (Graph Query Language), gRPC (Google Remote Procedure Call) ou outra tecnologia?
- Conclusão: Aqui as perguntas se tornam mais técnicas, o time de programação front-end vai transformar o protótipo em código, vai fazer a integração com o back-end e vai testar a interface para garantir que tudo está funcionando corretamente. Os testes são feitos envolvendo a equipe de qualidade (QA) caso exista e são feitos em dispositivos reais e em emuladores de dispositivos.
-
O time de testes vai perguntar:
- Quais são os cenários de teste que devem ser cobertos? Quais são os casos de uso mais comuns do aplicativo?
- Como será feito o teste de usabilidade? Será feito um teste com pessoas usuárias reais para validar a experiência do usuário?
- Como será feito o teste de performance? O aplicativo está respondendo rápido o suficiente? Ele está consumindo muita bateria? Ele está consumindo muita memória?
- Como será feito o teste de segurança? O aplicativo está protegido contra ataques de hackers? Ele está protegido contra vazamento de dados?
- Como serão feitos os testes de acessibilidade? O aplicativo está acessível? Ele está seguindo as diretrizes de acessibilidade da WCAG?
- Conclusão: O time de testes vai garantir que o aplicativo está funcionando corretamente, que a experiência do usuário é a melhor possível e que o aplicativo é seguro e acessível. Os testes de usabilidade infelizmente são os mais negligenciados, mas são essenciais para garantir que o aplicativo é fácil de usar e agradável de interagir para as pessoas com necessidades específicas. Os testes são feitos em dispositivos reais e em emuladores de dispositivos.
-
O time de programação back-end vai perguntar:
- Como será a integração com o front-end? Será usado REST, GraphQL, gRPC ou outra tecnologia?
- Como será a arquitetura do back-end? Será usado um padrão de arquitetura como MVC, MVVM, MVP, ou será feita uma arquitetura personalizada?
- Quais tecnologias serão usadas para desenvolver o back-end do aplicativo? Será usado Node.js, Java, Python, Ruby, PHP, C# ou outra tecnologia?
- Como será a integração com o banco de dados? Será usado MySQL, PostgreSQL, MongoDB, Redis, Cassandra ou outro banco de dados?
- Conclusão: O time de programação back-end vai garantir que o back-end está integrado com o front-end, que a arquitetura está correta, que as tecnologias estão funcionando corretamente e que o banco de dados está integrado.
-
Observação:
Os exemplos de tecnologias e padrões de arquitetura citados são apenas exemplos, não é preciso compreender cada um deles agora, o importante é entender o fluxo de desenvolvimento de um software.
Em resumo, o caminho do desenvolvimento é: o time de produtos faz a demanda, o time de design cria os protótipos, o time de programação front-end transforma os protótipos em código, o time de testes garante que o aplicativo está funcionando corretamente, o time de programação back-end garante que o back-end está integrado com o front-end e que o banco de dados está integrado corretamente.
Back-end é a parte do software que interage diretamente com o hardware do computador. É o que as pessoas não veem, mas que é essencial para o funcionamento do software. O back-end é responsável por processar informações, armazenar dados e executar operações complexas. É o back-end que faz o software ser rápido, seguro e confiável.
Um software apenas com front-end não é um software completo, é como um carro sem motor, ele pode ser bonito e agradável de interagir, mas não vai a lugar nenhum.
Por isso o fluxo descrito anteriormente é tão importante, o front-end e o back-end são partes de um mesmo software, eles precisam trabalhar juntos para que o software funcione corretamente.
Muitas das etapas descritas no fluxo anteriormente são desconhecidas para a maioria das pessoas, mas são essenciais para que um software seja desenvolvido e mantido.
Conhecendo as redes de computadores e sua importância
As redes de computadores foram desenvolvidas com o objetivo principal de permitir que dois ou mais dispositivos pudesse se comunicar para compartilhar recursos, sejam áudios, vídeos, arquivos e até mesmo controlar outras máquinas de forma remota. Atualmente as redes evoluíram e permitem a troca de informações entre diversos softwares (programas) sejam eles operados por pessoas para outras pessoas, para empresas ou programas que tornam possível a comunicação entre dispositivos sem a ação humana.
As redes de computadores são formadas por diferentes integrantes:
- Pessoas usuárias: são as pessoas que usam os dispositivos conectados à rede.
- Aplicações: são os programas que as pessoas usam para se comunicar com outras pessoas
- Roteadores: Esses são os dispositivos que conectam diferentes redes entre si. Eles são os responsáveis por encaminhar os dados de um dispositivo para outro.
- Switches: Esses são os dispositivos que conectam diferentes dispositivos dentro de uma rede. Eles são os responsáveis por encaminhar os dados de um dispositivo para o outro dentro da mesma rede.
- Servidores: São os dispositivos que armazenam e processam os dados de uma rede. Eles são os responsáveis por fornecer os dados para os dispositivos conectados à rede. Os sites e serviços que as pessoas acessam na internet são armazenados e processados em servidores.
- Meio físico cabeado: São os cabos de rede que conectam os dispositivos entre si. Eles são os meios de comunicação que permitem a troca de informações entre os dispositivos. Os cabos de rede são feitos de cobre ou fibra óptica e são usados para transmitir sinais elétricos ou luminosos.
- Meio físico aéreo: São as ondas de rádio que conectam os dispositivos entre si. Elas são os meios de comunicação que permitem a troca de informações entre os dispositivos. As ondas de rádio são usadas para transmitir sinais eletromagnéticos. Um exemplo de onda de rádio é o Wi-Fi.
- Protocolos para garantir a comunicação: São os acordos que permitem a comunicação entre os dispositivos. Eles são os meios de comunicação que permitem a troca de informações entre os dispositivos. Os protocolos são usados para garantir que os dados sejam transmitidos de forma segura e eficiente.
Para que um smartphone, tablet, notebook ou computador de mesa se conecte a uma rede é preciso uma placa de rede e que essa placa de rede esteja ligada por algum meio, seja ele físico ou aéreo, a um dispositivo de comunicação. É a placa de rede quem permite a transmissão dos sinais, seja por cabos ou pelo ar, esses mesmos sinais devem ser interpretados tanto pelo emissor quanto pelo receptor para que as informações possam ser exibidas para as pessoas que estão usando os programas.
Comparando com os sistemas de rádio e TV não é muito diferente, para que as informações (programas de rádio ou TV) fossem exibidos nos aparelhos também era preciso que os sinais fossem interpretados tanto pela estação que transmitia quanto pelo aparelho que recebia e tudo isso envolvia antenas.
Um dispositivo de comunicação, no contexto de uma rede de computadores, é aquele que vai receber dados em algum formato de um emissor e vai processá-lo, na sequência vai encaminhar os dados para o receptor da informação. Isso acontece independentemente de o dispositivo de comunicação estar, ou não, na mesma rede do emissor.

A imagem é um diagrama que mostra a conexão de vários dispositivos a uma rede de internet. No topo, há uma nuvem representando a "Internet", que está conectada a um "Modem". O modem, por sua vez, está conectado a um "Roteador".
Do roteador, saem conexões para diferentes dispositivos:
- À esquerda, um "Desktop" (computador de mesa).
- À direita, uma "Impressora" e uma "Camera IP".
- Abaixo, um "Smartphone", uma "SmartTV" e um "Notebook" (laptop).
O roteador está emitindo sinais de ondas, indicando a conexão sem fio (Wi-Fi) que alcança os dispositivos como o smartphone, a SmartTV e o notebook.
Observação: Em redes de computadores as informações ou dados que são trafegados entre os dispositivos e consumidos pelas pessoas são na maioria das vezes chamados de pacotes. Um pacote é um pequeno pedaço de uma mensagem maior (uma pequena parte). Os dados enviados por redes de computadores, como a Internet, são divididos em pequenos pacotes, esses pacotes são então recombinados pelo computador ou dispositivo que os recebe.
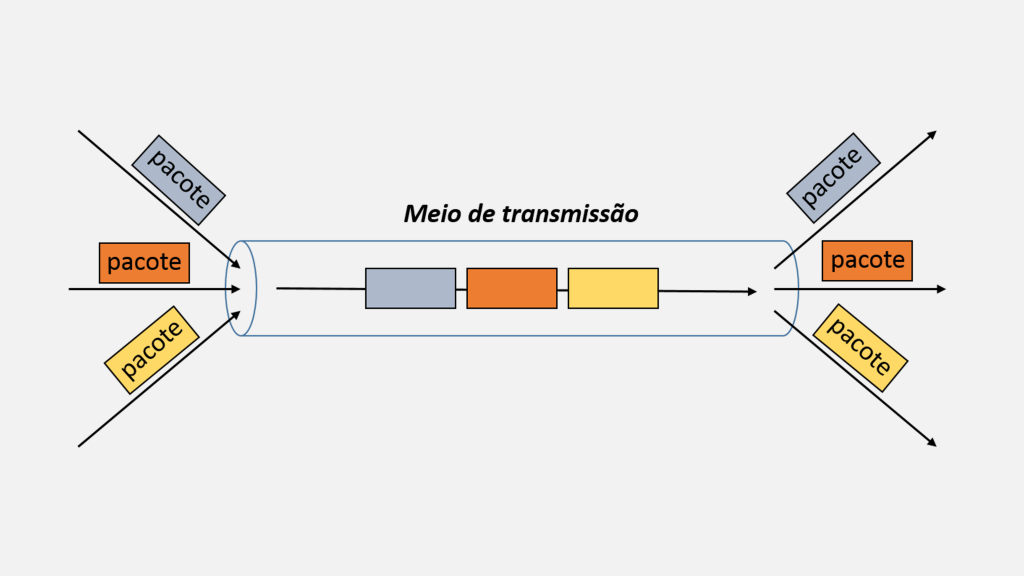
A imagem mostra um diagrama de transmissão de dados em rede. No centro, há um tubo horizontal rotulado como "Meio de transmissão".
À esquerda do tubo, três pacotes de dados, cada um com uma cor diferente (cinza, laranja e amarelo), estão entrando no meio de transmissão. Cada pacote é rotulado com a palavra "pacote".
Dentro do tubo, os pacotes são representados em fila, na mesma ordem de cores: cinza, laranja e amarelo.
À direita do tubo, os pacotes saem do meio de transmissão na mesma ordem em que entraram, cada um com sua respectiva cor e rótulo "pacote".
Como foi dito antes são muitos os elementos que formam uma rede de computador, cada um desses elementos funciona seguindo um conjunto de regras, para que os computadores possam estabelecer uma comunicação. É de se supor que toda a estrutura de rede é muito complexa, de se construir e de se entender, por isso foram criados modelos que funcionam como formas de simplificar o funcionamento e facilitar o entendimento, esses modelos tratam a organização das redes de computadores como se fossem camadas.
Os computadores trocam informações obedecendo a uma arquitetura que é dividida em camadas, cada camada possui suas próprias regras e protocolos bem definidos. Os dois modelos de camadas mais difundidos na área de redes são o modelo OSI e o modelo TCP/IP.
Modelo OSI
O modelo OSI (Open Systems Interconnection) foi criado pela ISO (International Organization for Standardization) com o objetivo de padronizar a comunicação entre computadores. Ele é composto por sete camadas, cada uma com suas próprias funções e responsabilidades. Na prática, ele não é usado em sua totalidade, mas é uma referência para entender como as redes de computadores funcionam.
As sete camadas do modelo OSI são:
- Física
- Enlace de dados
- Rede
- Transporte
- Sessão
- Apresentação
- Aplicação
As camadas do modelo OSI são organizadas de forma hierárquica, ou seja, cada camada é responsável por uma parte específica da comunicação entre computadores. A camada física, por exemplo, é responsável pela transmissão dos sinais elétricos ou luminosos que representam os dados. A camada de transporte, por sua vez, é responsável por garantir que os dados sejam transmitidos de forma segura e eficiente. Cada camada se comunica com as camadas adjacentes, ou seja, com a camada imediatamente acima e com a camada imediatamente abaixo.

A imagem é uma representação do Modelo OSI (Open System Interconnection Model), que é um modelo de referência para a interconexão de sistemas de comunicação. A imagem é predominantemente verde e está dividida em sete camadas, cada uma com uma breve descrição. As camadas são numeradas de 1 a 7, de baixo para cima. Aqui estão as camadas e suas descrições:
- Física: Ligação Física, cablagem
- Ligação de Dados: Controle de transmissão
- Rede: Gestão de endereçamento de dados
- Transporte: Controle de transporte de dados
- Sessão: Regras de comunicação
- Apresentação: Representação de dados
- Aplicação: Suporte de aplicações
O título "MODELO OSI" está no topo da imagem, seguido pela tradução em inglês "Open System Interconnection Model".
O modelo OSI é uma referência para entender como as redes de computadores funcionam, mas na prática ele não é usado em sua totalidade. A maioria das redes de computadores usa o modelo TCP/IP, que é mais simples e mais eficiente. No entanto, o modelo OSI é útil para entender os conceitos básicos de redes de computadores e como elas funcionam.
Modelo TCP/IP
O modelo TCP/IP (Transmission Control Protocol/Internet Protocol) é o modelo de referência mais usado em redes de computadores. Ele foi criado pelo Departamento de Defesa dos Estados Unidos com o objetivo de padronizar a comunicação entre computadores. Ele é composto por quatro camadas, cada uma com suas próprias funções e responsabilidades. O modelo TCP/IP é mais simples e mais eficiente que o modelo OSI, por isso é o mais usado na prática.
As quatro camadas do modelo TCP/IP são:
- Acesso a rede (também chamada de enlace)
- Internet (também chamada de rede)
- Transporte
- Aplicação
As funções gerais de cada camada do modelo TCP/IP são:
-
Acesso a rede
- Interface com a rede física: Isso quer dizer que a camada de acesso a rede é a responsável por fazer a comunicação entre o computador e a rede física, seja ela cabeada ou sem fio.
- Endereçamento físico dos hosts: Isso quer dizer que a camada de acesso a rede é a responsável por atribuir um endereço físico único a cada computador na rede, para que eles possam se comunicar entre si.
- Controle de acesso ao meio: Isso quer dizer que a camada de acesso a rede é a responsável por garantir que os computadores possam acessar a rede de forma segura e eficiente, evitando colisões e congestionamentos.
-
Internet
- Roteamento dos pacotes: Isso quer dizer que a camada de internet é a responsável por encaminhar os pacotes de um computador para outro, garantindo que eles cheguem ao destino correto.
- Endereçamento lógico dos hosts: Isso quer dizer que a camada de internet é a responsável por atribuir um endereço lógico único a cada computador na rede, para que eles possam se comunicar entre si.
-
Transporte
- Conexão ponto a ponto entre os processos: Isso quer dizer que a camada de transporte é a responsável por estabelecer uma conexão ponto a ponto entre os processos que estão se comunicando, garantindo que os dados sejam transmitidos de forma segura e eficiente.
- Aplicações que executam em hosts diferentes: Isso quer dizer que a camada de transporte é a responsável por garantir a comunicação entre aplicações que estão sendo executadas em servidores diferentes.
-
Aplicação
- Processo de rede para aplicações: Isso quer dizer que a camada de aplicação é a responsável por fazer a ponte entre os processos de rede e as aplicações que estão sendo executadas nos computadores. Em outras palavras, ela é a responsável por fazer a comunicação entre os processos de rede e as aplicações, essa comunicação é feita através de protocolos.
- Representação das mensagens: Isso quer dizer que a camada de aplicação é a responsável por fazer a representação (estruturação) das mensagens que são trocadas entre os hosts (computadores) e as aplicações na rede. Isso inclui a codificação e a montagem das mensagens.
- Formatação das mensagens: Isso quer dizer que a camada de aplicação é a responsável também por fazer a formatação (organização) das mensagens que são trocadas entre os hosts (computadores) e as aplicações na rede. Ela é a responsável por dar a forma correta para as mensagens, para que elas possam ser interpretadas do outro lado da comunicação sem erros.
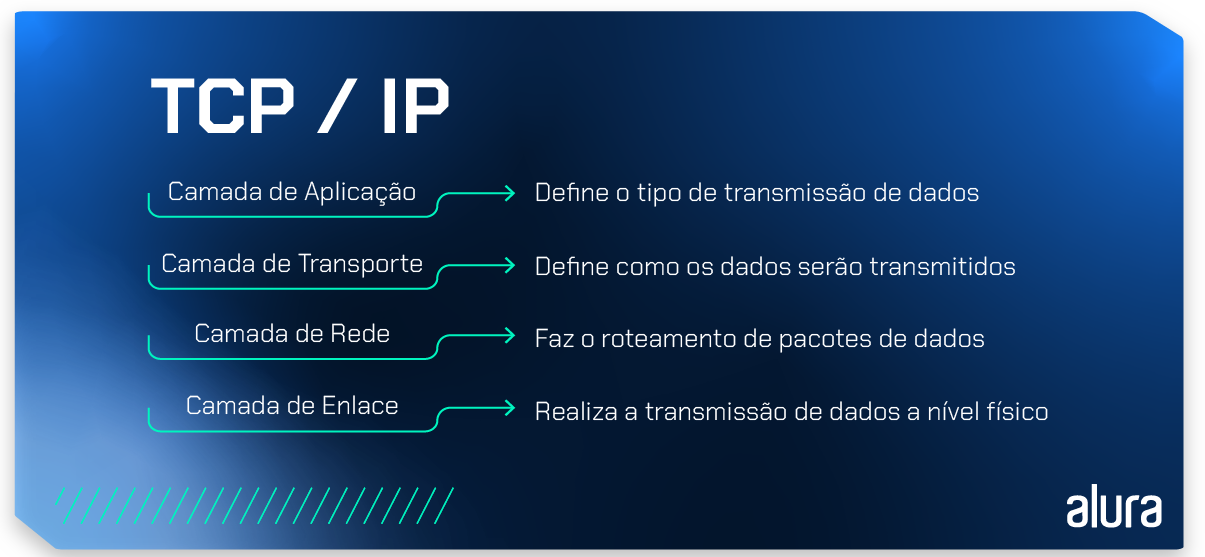
Este diagrama apresenta o modelo TCP/IP, que é um conjunto de protocolos de comunicação usados na internet. O modelo é dividido em quatro camadas, cada uma com uma função específica descrita em português:
- Camada de Aplicação: Define o tipo de transmissão de dados
- Camada de Transporte: Define como os dados serão transmitidos
- Camada de Rede: Faz o roteamento de pacotes de dados
- Camada de Enlace: Realiza a transmissão de dados a nível físico

A imagem é um diagrama que ilustra o processo de comunicação de dados entre uma origem e um receptor, seguindo o modelo de camadas TCP. O fundo é azul escuro e o texto é branco e verde.
À esquerda, está a "Origem" que "Envia dados". Abaixo, há uma seta indicando que os "Dados sendo empacotados e passados para a camada inferior". As camadas listadas são:
- Camada de Aplicação
- Camada de Transporte
- Camada de Rede
- Camada de Enlace
À direita, está o "Receptor", os dados chegam nas camadas do receptor na mesma ordem que saem da origem, mas no sentido inverso. Na origem, os dados são empacotados e passam pelas camadas de cima para baixo (Aplicação, Transporte, Rede, Enlace). No receptor, os dados são desempacotados e passam pelas camadas de baixo para cima (Enlace, Rede, Transporte, Aplicação). Isso garante que a informação seja corretamente interpretada e entregue ao destino final.
O modelo TCP/IP é uma referência para entender como as redes de computadores funcionam na prática. Ele é mais simples e mais eficiente que o modelo OSI, por isso é o mais usado na maioria das redes de computadores. O modelo TCP/IP é a base da comunicação na internet e é essencial para o funcionamento da rede. Ele define como os dados são transmitidos, como os computadores se identificam e como as mensagens são estruturadas. Os protocolos do modelo TCP/IP são a base da comunicação na internet e são essenciais para o funcionamento da rede.
Protocolos de comunicação da internet
Protocolos são acordos que permitem a comunicação, eles são como as regras de um jogo, sem eles a comunicação não acontece.
Exemplo
André pergunta:
— Que horas são?
Carla responde:
— Agora são dez da manhã!
Existe um protocolo de comunicação padronizado entre André e Carla, os dois sabem o que são horas, os dois sabem reconhecer a forma de montar uma pergunta em português do Brasil, os dois sabem como montar a resposta para a pergunta e os dois sabem seus lugares André como o receptor e Carla como a emissora da informação, neste caso a hora.
Da mesma forma, na internet, os computadores precisam de protocolos para se comunicar. Os protocolos de comunicação da internet são acordos que permitem a troca de informações entre computadores. Eles definem como os dados são transmitidos, como os computadores se identificam e como as mensagens são estruturadas.
O modelo TCP/IP define quatro camadas, todas essas camadas possuem protocolos. Esses protocolos levam em consideração um conjunto de fatores, como:
- O serviço que será oferecido.
- O ambiente de execução, incluindo os serviços usados pelo próprio protocolo (como o DNS, por exemplo).
- O vocabulário de mensagens usado para implantar o protocolo. O vocabulário é o conjunto de mensagens que o protocolo pode enviar e receber.
- O formato que cada mensagem do vocabulário é construída. O formato é a forma como a mensagem é codificada.
- Os algoritmos usados, que tentam garantir a entrega das mensagens e a integridade do serviço. Por exemplo, o DNS usa algoritmos para garantir que os IP são únicos.
Resumindo: Os protocolos de comunicação da internet são acordos que permitem a troca de informações entre computadores. Eles definem como os dados são transmitidos, como os computadores se identificam e como as mensagens são estruturadas. Os protocolos são a base da comunicação na internet e são essenciais para o funcionamento da rede.
Levando isso em consideração, o foco agora será direcionado para os protocolos das camadas do modelo TCP/IP. Nesse modelo, existem três protocolos bem importantes. São eles:
-
IP (Internet Protocol / Protocolo de Internet) - TCP (Transmission Control Protocol / Protocolo de Controle de Transmissão)
- UDP (User Datagram Protocol / Protocolo de Datagrama do Usuário)
Onde:
- IP - Internet Protocol: Está na camada de rede.
- TCP - Transmission Control Protocol: Está na camada de transporte.
- UDP - User Datagram Protocol: Está na camada de transporte.
Responsabilidades do IP
- Endereçamento: É como o seu computador sabe para onde enviar as informações.
- Determinação de caminhos: É como o seu computador decide qual caminho seguir para enviar as informações. Isso é feito por algoritmos especiais.
- Comutação (ou repasse): É o processo de mover informações de um lugar para outro.
Responsabilidades do TCP
- A origem: É onde as informações começam, ele pega os dados, divide-os em partes menores se necessário, os envia e garante que eles cheguem ao destino corretamente.
- Isolamento: Isso significa que as mudanças na tecnologia do computador (hardware) não afetam a maneira como as informações são enviadas.
- Entidade de transporte: É o hardware ou software que executa as funções de envio de informações. Pode ser o sistema operacional do seu computador, bibliotecas de rede, placas de rede etc.
UDP – User Datagram Protocol
O UDP, ou User Datagram Protocol (Protocolo de Datagrama do Usuário, em português), é uma parte do modelo TCP/IP, a principal coisa para se entender sobre o UDP é que ele é como enviar cartas sem a confirmação de recebimento. Quando você envia uma carta, você a coloca no correio e espera que ela chegue ao destino. Você não recebe uma confirmação de que a carta foi entregue. Da mesma forma, o UDP envia informações de um computador para outro na internet sem garantia de que a informação foi realmente recebida, isso pode ser rápido, mas também pode significar que algumas informações podem se perder no caminho.
Em comparação com o TCP (Transmission Control Protocol), que é mais como enviar uma carta com aviso de recebimento, o UDP é mais rápido, mas não garante a entrega ou a ordem exata das informações. Então, em resumo, o UDP é um jeito rápido de enviar informações pela internet, mas sem garantia de que elas chegarão corretamente. Isso é útil em situações em que a velocidade é mais importante do que ter certeza de que todas as informações foram recebidas corretamente como por exemplo em chamadas de voz, conferências ao vivo pelo Google Meet etc.
A World Wide Web (WWW)
As ideias que dariam origem à World Wide Web (WWW) começaram na década de 1980 no CERN, na Suíça. Movido pelo objetivo de facilitar o compartilhamento de pesquisas e documentos científicos, o pesquisador Tim Berners-Lee, em 1989, iniciou um projeto para melhor gerenciar essas informações.
Tim Berners-Lee, juntamente com Robert Cailliau, baseou-se em um sistema chamado ENQUIRE para idealizar os primeiros rascunhos da WWW. Em 1990, Lee usou pela primeira vez o computador NeXTCube, desenvolvido pela NeXT, empresa de Steve Jobs criada em 1985. Lee utilizou este computador para escrever o primeiro servidor web e o primeiro navegador web, chamado WorldWideWeb.
A WWW nasceu em 1991, junto com ela um novo protocolo foi criado para atender às necessidades da comunidade científica em trabalhar com hipertexto: o HTTP - Hypertext Transfer Protocol. O hipertexto é extremamente importante para a internet como um todo, sendo um conceito debatido desde a década de 1960. O que Lee fez foi unir o hipertexto com a internet. Vamos explicar o que essa palavra significa afinal.
"De forma bem simplificada, pode-se dizer que o termo hipertexto designa uma escritura não-sequencial e não-linear, que se ramifica de modo a permitir ao leitor virtual o acesso praticamente ilimitado a outros textos, na medida em que procede a escolhas locais e sucessivas em tempo real." (KOCH, I. G. V, 2007, Hipertexto e Construção do Sentido)
Em outras palavras: hipertexto refere-se a uma forma de escrever que não segue uma ordem linear, mas se ramifica, permitindo que o leitor online acesse muitos outros textos. Em vez de seguir uma linha reta, o hipertexto é não-sequencial e não-linear. Isso significa que, ao invés de ler de uma página para outra em ordem predefinida, você pode seguir diferentes caminhos, escolhendo links ou opções ao longo do texto.
Imagine o hipertexto como uma rede interconectada de informações, onde cada nó representa um pedaço de texto e os links são as conexões entre eles. Essas conexões permitem que você salte de um ponto para outro, explorando tópicos relacionados ou complementares. Em essência, o hipertexto oferece ao leitor virtual a liberdade de explorar uma vasta quantidade de informações de maneira não linear.
Hoje em dia, essa abordagem é especialmente comum na internet. Quando alguém está lendo um texto na Wikipédia e não sabe o que uma determinada palavra significa, essa pessoa pode clicar na palavra e ser direcionada para outro texto com seu significado. Isso é hipertexto. Hoje é simples pensar em links conectando textos para facilitar o entendimento de algo, mas esse conceito não é restrito à internet.
O hipertexto é a base da internet, mas essa ideia surgiu antes da própria internet. Na década de 1960, as pessoas já pensavam em como usar links em palavras para conectar conceitos e facilitar o entendimento de algo, sobretudo de termos científicos. O que Tim Berners-Lee fez foi juntar o conceito de hipertexto com a ideia de internet (uma rede mundial de computadores conectada), mas não encontrou apoio para construir sua ideia. Então, Lee decidiu construir seu projeto sozinho. Com esse projeto, ele também criou um sistema de identificação global e único de recursos, chamado Uniform Resource Identifier – URI, que mais tarde se tornaria a URL (Uniform Resource Locator que é o endereço de uma página na internet) que conhecemos hoje.
HTML, CSS, Javascript

Até aqui, é possível perceber que um programa para atender as necessidades das pessoas precisa estar estruturado, ser atraente (bonito e chamativo) e funcional. Não adianta ser lindo e mal organizado, assim como não adianta ser organizado e muito, muito lento ou perder dados importantes com frequência, o que tornaria o sistema instável e não confiável.
Ainda pensando que um programa para atender as necessidades das pessoas precisa ser estruturado, atraente e funcional, pode-se dizer que na internet existe um tripé básico para atender a esses requisitos: HTML, CSS e JavaScript. Essas três tecnologias são chamadas de tripé da web porque são a base de sustentação para todas as outras, sendo imprescindível o conhecimento básico acerca delas para entender todo o resto.
HTML
No vasto universo da internet, onde clicamos, exploramos e nos conectamos, há uma linguagem fundamental que desempenha o papel de arquiteto digital, moldando as páginas que visualizamos diariamente: o HTML, sigla para Hypertext Markup Language, ou Linguagem de Marcação de Hipertexto. Para compreendermos melhor essa linguagem, é como se pensássemos em uma receita de bolo para a web.
Imagine a internet como uma grande confeitaria, cheia de guloseimas digitais prontas para serem degustadas. O HTML seria a receita básica que dá forma a essas delícias virtuais. Cada página web é como um bolo único, e o HTML é o conjunto de instruções que diz ao navegador como organizá-la, onde colocar cada ingrediente (texto, imagens, links) e como apresentá-la ao público.
Ao longo dos anos, essa receita evoluiu para uma versão mais moderna e poderosa chamada HTML5. Imagine que o HTML5 é como uma versão aprimorada da receita original, incorporando novos ingredientes e técnicas culinárias mais avançadas. Essa evolução não apenas torna as páginas web mais bonitas e interativas, mas também as torna mais eficientes e adaptáveis aos diferentes dispositivos que usamos, como smartphones e tablets.
Uma das grandes melhorias do HTML5 é a capacidade de incorporar elementos multimídia diretamente na receita. Antes, era como se a página web só pudesse exibir fotos estáticas, agora, com o HTML5, podemos incluir vídeos, animações e até mesmo música, proporcionando uma experiência mais rica e envolvente para quem navega na web. Outra característica notável do HTML5 é a ênfase na semântica, ou seja, na clareza do significado do conteúdo.
Isso facilita não apenas para os navegadores, mas também para outros softwares e até mesmo para pessoas com deficiência compreenderem e interagirem melhor com o conteúdo online. É como se a receita não apenas dissesse onde colocar os ingredientes, mas também explicasse por que cada um deles é importante.
Em resumo, o HTML e o HTML5 são as receitas digitais que moldam o visual e o funcionamento da internet. O HTML5, como uma versão mais avançada, traz melhorias significativas, tornando a experiência online mais rica e acessível.
CSS
Se o HTML é a receita básica que dá forma às páginas web, o CSS, sigla para Cascading Style Sheets, ou Folhas de Estilo em Cascata, é o toque final que as torna bonitas e atraentes. Imagine que o HTML é a estrutura de um bolo, com suas camadas e recheios, enquanto o CSS é a cobertura colorida e decorativa que o torna irresistível.
O CSS é a linguagem que define a aparência visual de uma página web, controlando aspectos como cores, fontes, espaçamento, layout e muito mais. É como se fosse o estilista digital que escolhe as roupas e acessórios ideais para vestir a página, garantindo que ela fique elegante e harmoniosa. Sem o CSS, as páginas web seriam como bolos sem cobertura, funcionais, mas sem ser atraentes.
Uma das grandes vantagens do CSS é a capacidade de separar o conteúdo da apresentação. Isso significa que podemos manter a estrutura e o significado do conteúdo (HTML) separados da sua aparência visual (CSS), facilitando a manutenção e a atualização das páginas web. Imagine que seu site está estruturado e você deseja mudar a cor de fundo de todas as páginas. Com o CSS, você pode fazer essa alteração em um único lugar, no arquivo de estilos, e ela será aplicada automaticamente a todas as páginas, sem a necessidade de alterar página por página no HTML.
Além disso, o CSS permite criar estilos reutilizáveis e modulares, que podem ser aplicados a diferentes partes do site de forma consistente. Isso não apenas economiza tempo e esforço, mas também garante uma experiência visual coesa e profissional para os visitantes. Com o CSS, é possível criar layouts complexos, animações interativas e designs responsivos que se adaptam a diferentes dispositivos e tamanhos de tela.
Javascript
Se o HTML é a receita básica e o CSS é a cobertura decorativa, o Javascript é o ingrediente especial que adiciona sabor e interatividade às páginas web. Imagine que o HTML e o CSS são os ingredientes principais de um bolo, enquanto o Javascript é o tempero que dá o toque final, tornando-o único e memorável.
O Javascript é uma linguagem de programação que permite adicionar funcionalidades dinâmicas e interativas às páginas web. É como se fosse o chef digital que cria experiências personalizadas e envolventes para os visitantes, tornando a navegação mais fluida e agradável. Sem o Javascript, as páginas web seriam estáticas e limitadas, sem a capacidade de responder às ações das pessoas.
Uma das grandes vantagens do Javascript é a capacidade de manipular o conteúdo da página em tempo real, sem a necessidade de recarregar a página. Isso permite criar elementos interativos, como botões, menus, formulários e animações, que respondem instantaneamente aos cliques e toques dos usuários. Imagine que você deseja exibir uma mensagem de boas-vindas quando alguém entra no site. Com o Javascript, você pode fazer isso de forma dinâmica, sem a necessidade de recarregar a página.
Além disso, o Javascript permite acessar e modificar o conteúdo da página, interagir com o usuário, enviar e receber dados do servidor e muito mais.
Em resumo, esse é o tripé da web: HTML, CSS e Javascript. O HTML fornece a estrutura, o CSS fornece o estilo e o Javascript fornece a interatividade. Juntos, esses três ingredientes formam a base sólida sobre a qual a internet é construída, permitindo que as pessoas desenvolvedoras criem aplicações web estruturadas, bonitas e funcionais.
Frameworks
Imagine que você está construindo uma casa, construir uma casa do zero pode ser um processo demorado e complicado, você precisa projetar a planta da casa, instalar encanamento, eletricidade, janelas e muito mais. No entanto, há uma maneira mais fácil de fazer isso: usando um kit de construção de casas. Este kit já contém as peças principais de uma casa, como paredes, portas, janelas e telhados, tornando a construção muito mais rápida e simples, os kits de construção de casas são como frameworks na tecnologia.
Em termos tecnológicos, um framework é como um "kit de construção" que as pessoas desenvolvedoras de software usam para criar aplicativos ou sites mais facilmente e de forma mais eficiente. Em vez de começar do zero, eles usam um framework que fornece componentes e funcionalidades básicas já pré-construídas. Isso economiza tempo e esforço, permitindo que as pessoas se concentrem em aspectos específicos de seus projetos ao invés de projetar toda infraestrutura de HTML, CSS e Javascript do zero toda vez que iniciam um projeto novo. Alguns exemplos de frameworks populares são:
- Bootstrap: Framework CSS que oferece estilos, layouts e componentes (botões, menus e outros) já prontos para uso;
- Ruby on Rails: Imagine que na construção da casa já exista um conjunto de planos e diretrizes para orientar a construção seguindo o melhor padrão possível. Ruby on Rails fornece estruturas e regras que simplificam o desenvolvimento de aplicativos web. Ruby on Rails é o framework para a linguagem de programação Ruby, bastante usada na construção de back-end, um exemplo de site que usa é o GitHub;
- Angular e React (para Javascript): Esses frameworks são como conjuntos de ferramentas para a construção de interfaces de usuário interativas na web. Eles fornecem componentes e funcionalidades para criar páginas da web dinâmicas com elementos que possam ser reutilizados.
Em resumo, um framework é como um conjunto de ferramentas e recursos pré-construídos que facilitam a vida das pessoas desenvolvedoras, permitindo que elas construam software de forma mais eficiente, como usar um kit de construção para uma casa em vez de começar do zero. Eles são uma parte essencial da tecnologia moderna, tornando o desenvolvimento de software mais rápido e acessível.
Considerações finais
A área de tecnologia é notoriamente dinâmica e multifacetada, apresentando vastas e variadas oportunidades para profissionais com diferentes níveis de formação e experiência. Este artigo buscou oferecer uma visão abrangente e detalhada sobre a formação acadêmica necessária e as diversas possibilidades de atuação profissional nesse campo. Desde os cursos tradicionais como Ciência da Computação, Engenharia da Computação e Sistemas de Informação até as graduações tecnológicas mais focadas e práticas, a tecnologia se revela como um campo rico em opções para aqueles que desejam construir uma carreira sólida e impactante.
Em relação à atuação profissional, a flexibilidade e a diversidade de possibilidades são evidentes. Profissionais de tecnologia podem encontrar oportunidades em setores públicos ou privados, em empresas de tecnologia, em consultorias e como freelancers, desenvolvendo projetos que variam de sistemas corporativos complexos a sites e aplicações para pequenas empresas e eventos. Essa diversidade de caminhos profissionais é fortalecida pela ausência de regulamentações rígidas, como as encontradas em outras profissões, permitindo que indivíduos de diferentes formações e backgrounds possam ingressar e prosperar na área.
Além das formações e possibilidades de carreira, este artigo explorou os fundamentos técnicos que sustentam a área de tecnologia, desde a estrutura básica dos computadores, com seus componentes de hardware e software, até a importância das redes de computadores e da internet. O entendimento desses fundamentos é crucial para qualquer profissional que deseja aprofundar seu conhecimento e se destacar no campo da tecnologia.
O tripé básico da web, composto por HTML, CSS e JavaScript, foi discutido como a base essencial para o desenvolvimento de páginas e aplicações web, destacando a importância de frameworks que facilitam e agilizam o processo de desenvolvimento. Esse conhecimento é vital para a criação de experiências digitais ricas, interativas e eficientes, que atendam às necessidades de usuários e empresas.
Em suma, a área de tecnologia é um campo de oportunidades sem precedentes, onde a inovação e a evolução são as únicas constantes. Para aqueles que estão iniciando ou desejam aprofundar seu conhecimento, este artigo serve como um guia detalhado e abrangente, oferecendo insights valiosos sobre a formação acadêmica, as possibilidades de carreira e os fundamentos técnicos essenciais para prosperar neste campo. A tecnologia continua a moldar o mundo ao nosso redor, e os profissionais que se dedicam a entender e dominar essa área estão na vanguarda dessa transformação contínua.
Apesar de pouco usual, este artigo optou por uma abordagem mais teórica e conceitual em relação à tecnologia, com o intuito de fornecer uma base sólida e abrangente para quem deseja ingressar nesse campo. Os aspectos práticos e técnicos da tecnologia serão abordados em futuros artigos com focos específicos, mas tendo como base os conceitos e fundamentos apresentados aqui.
Referências
- A História do Front-End para Iniciantes em Programação | Série "Começando aos 40" - por Fábio Akita em Akita on Rails. Disponível em: https://www.akitaonrails.com/2019/02/13/akitando-39-a-historia-do-front-end-para-iniciantes-em-programacao-serie-comecando-aos-40
- Aprenda a estilizar HTML utilizando CSS - por Mozilla Developer Network. Disponível em: https://developer.mozilla.org/pt-BR/docs/Learn/CSS
- Como funciona a Internet? - por Mozilla Developer Network. Disponível em: https://developer.mozilla.org/en-US/docs/Learn/Common_questions/Web_mechanics/How_does_the_Internet_work
- Como funciona a Web? - por Mozilla Developer Network. Disponível em: https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/How_the_Web_works
- Estruturando a Web com HTML5 - por Mozilla Developer Network. Disponível em: https://developer.mozilla.org/pt-BR/docs/Learn/HTML
- JavaScript - por Mozilla Developer Network. Disponível em: https://developer.mozilla.org/pt-BR/docs/Learn/JavaScript
- O Mercado de TI para Iniciantes em Programação | Série "Começando aos 40" - por Fábio Akita em Akita on Rails. Disponível em: https://www.akitaonrails.com/2019/01/23/akitando-36-o-mercado-de-ti-para-iniciantes-em-programacao-serie-comecando-aos-40
- O que é um Framework? - por Wikipédia. Disponível em: https://pt.wikipedia.org/wiki/Framework
- TANENBAUM, Andrew S.; WOODHULL, Albert S. Sistemas operacionais: projeto e implementação. Porto Alegre: Bookman. 2008.
- TANENBAUM, Andrew S. Structured Computer Organization. 6th ed. Pearson, 2013.